






 BTC/HKD-0.2%
BTC/HKD-0.2% ETH/HKD+0.35%
ETH/HKD+0.35% LTC/HKD+0.01%
LTC/HKD+0.01% DOT/HKD+2.09%
DOT/HKD+2.09% ADA/HKD+1.59%
ADA/HKD+1.59% SOL/HKD+3.88%
SOL/HKD+3.88% XRP/HKD+0.33%
XRP/HKD+0.33% DOGE/US+0.54%
DOGE/US+0.54%ChatGPT是個啥?
近期,OpenAI發布了ChatGPT,是一個可以對話的方式進行交互的模型,因為它的智能化,得到了很多用戶的歡迎。ChatGPT也是OpenAI之前發布的InstructGPT的親戚,ChatGPT模型的訓練是使用RLHF也許ChatGPT的到來,也是OpenAI的GPT-4正式推出之前的序章。
什么是GPT?從GPT-1到GPT-3
GenerativePre-trainedTransformer(GPT),是一種基于互聯網可用數據訓練的文本生成深度學習模型。它用于問答、文本摘要生成、機器翻譯、分類、代碼生成和對話AI。
2018年,GPT-1誕生,這一年也是NLP的預訓練模型元年。性能方面,GPT-1有著一定的泛化能力,能夠用于和監督任務無關的NLP任務中。其常用任務包括:
自然語言推理:判斷兩個句子的關系問答與常識推理:輸入文章及若干答案,輸出答案的準確率語義相似度識別:判斷兩個句子語義是否相關分類:判斷輸入文本是指定的哪個類別雖然GPT-1在未經調試的任務上有一些效果,但其泛化能力遠低于經過微調的有監督任務,因此GPT-1只能算得上一個還算不錯的語言理解工具而非對話式AI。
Cobo與美國受監管加密平臺Legend Trading達成合作推出場外交易服務:金色財經報道,據數字資產托管解決方案提供商Cobo官推宣布已與美國受監管加密貨幣交易公司Legend Trading達成戰略合作伙伴關系,并將 Legend Trading 的場外交易 (OTC) 交易服務整合到 Cobo 的平臺中,Cobo錢包用戶將能在KYC流出完成后獲得加密貨幣定價、加密交易執行和深度流動性服務。[2023/6/17 21:43:34]
GPT-2也于2019年如期而至,不過,GPT-2并沒有對原有的網絡進行過多的結構創新與設計,只使用了更多的網絡參數與更大的數據集:最大模型共計48層,參數量達15億,學習目標則使用無監督預訓練模型做有監督任務。在性能方面,除了理解能力外,GPT-2在生成方面第一次表現出了強大的天賦:閱讀摘要、聊天、續寫、編故事,甚至生成假新聞、釣魚郵件或在網上進行角色扮演通通不在話下。在“變得更大”之后,GPT-2的確展現出了普適而強大的能力,并在多個特定的語言建模任務上實現了彼時的最佳性能。
之后,GPT-3出現了,作為一個無監督模型,幾乎可以完成自然語言處理的絕大部分任務,例如面向問題的搜索、閱讀理解、語義推斷、機器翻譯、文章生成和自動問答等等。而且,該模型在諸多任務上表現卓越,例如在法語-英語和德語-英語機器翻譯任務上達到當前最佳水平,自動產生的文章幾乎讓人無法辨別出自人還是機器,更令人驚訝的是在兩位數的加減運算任務上達到幾乎100%的正確率,甚至還可以依據任務描述自動生成代碼。一個無監督模型功能多效果好,似乎讓人們看到了通用人工智能的希望,可能這就是GPT-3影響如此之大的主要原因
以太坊Layer 2網絡TVL突破90億美元,創歷史新高:金色財經報道,數據顯示,以太坊Layer 2網絡總鎖倉量(TVL)突破90億美元,創歷史新高,當前約為90.1億美元。其中Arbitrum One上TVL約59.8億美元,Optimism上TVL約20.2億美元,二者占總TVL的近90%。[2023/3/24 13:24:24]
GPT-3模型到底是什么?
實際上,GPT-3就是一個簡單的統計語言模型。從機器學習的角度,語言模型是對詞語序列的概率分布的建模,即利用已經說過的片段作為條件預測下一個時刻不同詞語出現的概率分布。語言模型一方面可以衡量一個句子符合語言文法的程度,同時也可以用來預測生成新的句子。例如,對于一個片段“中午12點了,我們一起去餐廳”,語言模型可以預測“餐廳”后面可能出現的詞語。一般的語言模型會預測下一個詞語是“吃飯”,強大的語言模型能夠捕捉時間信息并且預測產生符合語境的詞語“吃午飯”。
通常,一個語言模型是否強大主要取決于兩點:首先看該模型是否能夠利用所有的歷史上下文信息,上述例子中如果無法捕捉“中午12點”這個遠距離的語義信息,語言模型幾乎無法預測下一個詞語“吃午飯”。其次,還要看是否有足夠豐富的歷史上下文可供模型學習,也就是說訓練語料是否足夠豐富。由于語言模型屬于自監督學習,優化目標是最大化所見文本的語言模型概率,因此任何文本無需標注即可作為訓練數據。
非營利性志愿者組織New York Cares通過出售NFT籌集資金:10月13日消息,非營利性志愿者組織New York Cares通過出售NFT為Stand with Students籌集資金,這是一項幫助支持當地公立學校的舉措。該系列將包含由Open AI的DALL-E創建的超過16,000件數字作品。(CoinDesk)[2022/10/13 14:26:41]
由于GPT-3更強的性能和明顯更多的參數,它包含了更多的主題文本,顯然優于前代的GPT-2。作為目前最大的密集型神經網絡,GPT-3能夠將網頁描述轉換為相應代碼、模仿人類敘事、創作定制詩歌、生成游戲劇本,甚至模仿已故的各位哲學家——預測生命的真諦。且GPT-3不需要微調,在處理語法難題方面,它只需要一些輸出類型的樣本。可以說GPT-3似乎已經滿足了我們對于語言專家的一切想象。
注:上文主要參考以下文章:1.GPT4發布在即堪比人腦,多位圈內大佬坐不住了!-徐杰承、云昭-公眾號51CTO技術棧-2022-11-2418:082.一文解答你對GPT-3的好奇!GPT-3是什么?為何說它如此優秀?-張家俊中國科學院自動化研究所2020-11-1117:25發表于北京3.TheBatch:329|InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-0712:30
Solana 鏈上項目 Squads V3 已上線 app:金色財經消息,Squads 發推特稱其 Squads V3 已上線 app。Squads V3 致力于為 Solana 生態系統提供多重簽名解決方案。
據悉,Squads 發在今年2月完成500萬美元戰略融資,由 Multicoin Capital 領投。[2022/8/17 12:30:43]
GPT-3存在什么問題?
但是GTP-3并不完美,當前有人們最擔憂人工智能的主要問題之一,就是聊天機器人和文本生成工具等很可能會不分青紅皂白和質量好壞,地對網絡上的所有文本進行學習,進而生產出錯誤的、惡意冒犯的、甚至是攻擊性的語言輸出,這將會充分影響到它們的下一步應用。
OpenAI也曾經提出,會在不久的將來發布更為強大的GPT-4:

將?GPT-3與GPT-4、?人腦進行比較
據說,GPT-4會在明年發布,它能夠通過圖靈測試,并且能夠先進到和人類沒有區別,除此之外,企業引進GPT-4的成本也將大規模下降。
Alameda Research地址已清倉其持有的APE:8月10日消息,鏈上標記為“Alameda Research”(0xc5ed2333f8a2C351fCA35E5EBAdb2A82F5d254C3)的地址于北京時間8月9日12:42:30賣出其所持有的全部184,266.3枚APE。據DeBank當前數據顯示,該地址所持有的APE Token已小于1美元。[2022/8/10 12:14:48]
ChatGP與InstructGPT
ChatGPT與InstructGPT
談到Chatgpt,就要聊聊它的“前身”InstructGPT。
2022年初,OpenAI發布了InstructGPT;在這項研究中,相比GPT-3而言,OpenAI采用對齊研究,訓練出更真實、更無害,而且更好地遵循用戶意圖的語言模型InstructGPT,InstructGPT是一個經過微調的新版本GPT-3,可以將有害的、不真實的和有偏差的輸出最小化。
InstructGPT的工作原理是什么?
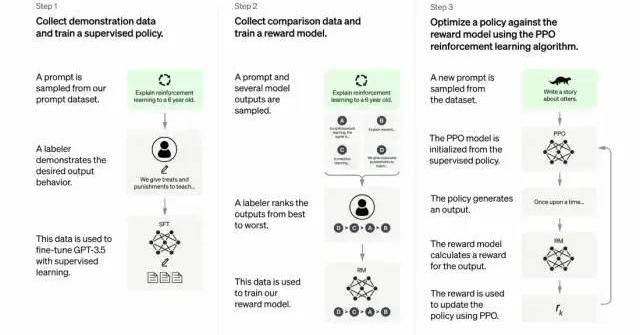
開發人員通過結合監督學習+從人類反饋中獲得的強化學習。來提高GPT-3的輸出質量。在這種學習中,人類對模型的潛在輸出進行排序;強化學習算法則對產生類似于高級輸出材料的模型進行獎勵。
訓練數據集以創建提示開始,其中一些提示是基于GPT-3用戶的輸入,比如“給我講一個關于青蛙的故事”或“用幾句話給一個6歲的孩子解釋一下登月”。
開發人員將提示分為三個部分,并以不同的方式為每個部分創建響應:
人類作家會對第一組提示做出響應。開發人員微調了一個經過訓練的GPT-3,將它變成InstructGPT以生成每個提示的現有響應。
下一步是訓練一個模型,使其對更好的響應做出更高的獎勵。對于第二組提示,經過優化的模型會生成多個響應。人工評分者會對每個回復進行排名。在給出一個提示和兩個響應后,一個獎勵模型(另一個預先訓練的GPT-3)學會了為評分高的響應計算更高的獎勵,為評分低的回答計算更低的獎勵。
開發人員使用第三組提示和強化學習方法近端策略優化(ProximalPolicyOptimization,PPO)進一步微調了語言模型。給出提示后,語言模型會生成響應,而獎勵模型會給予相應獎勵。PPO使用獎勵來更新語言模型。
本段參考:TheBatch:329|InstructGPT,一種更友善、更溫和的語言模型-公眾號DeeplearningAI-2022-02-0712:30
重要在何處?核心在于——人工智能需要是能夠負責任的人工智能
OpenAI的語言模型可以助力教育領域、虛擬治療師、寫作輔助工具、角色扮演游戲等,在這些領域,社會偏見、錯誤信息和害信息存在都是比較麻煩的,能夠避免這些缺陷的系統才能更具備有用性。
Chatgpt與InstructGPT的訓練過程有哪些不同?
總體來說,Chatgpt和上文的InstructGPT一樣,是使用RLHF訓練的。不同之處在于數據是如何設置用于訓練的。
ChatGPT存在哪些局限性?
如下:a)在訓練的強化學習(RL)階段,沒有真相和問題標準答案的具體來源,來答復你的問題。b)訓練模型更加謹慎,可能會拒絕回答。c)監督訓練可能會誤導/偏向模型傾向于知道理想的答案,而不是模型生成一組隨機的響應并且只有人類評論者選擇好的/排名靠前的響應
注意:ChatGPT對措辭敏感。,有時模型最終對一個短語沒有反應,但對問題/短語稍作調整,它最終會正確回答。訓練者更傾向于喜歡更長的答案,因為這些答案可能看起來更全面,導致傾向于更為冗長的回答,以及模型中會過度使用某些短語,如果初始提示或問題含糊不清,則模型不會適當地要求澄清。
近日,香港立法會議員吳杰莊在參加一場虛擬資產新政討論的TwitterSpace中透露,2023年1月9-10日將在香港舉行Web3創新者峰會,邀請所有加密產業的華人創業者“回家過年”.
1900/1/1 0:00:00Web3開啟了在全球范圍內協調人類活動的新方法。Web3網絡具有無國界和無地域偏見的獨特特征,它只承認個人對網絡的貢獻.
1900/1/1 0:00:00SEC的主席GaryGensler,正處于一場關于加密貨幣未來的清算中心。今年3月,也就是SBF的加密貨幣帝國崩盤的八個月前,他加入了與GaryGensler的視頻通話.
1900/1/1 0:00:00雖然Crypto處于熊市,但是顯然Defi的Builder們可沒有太多的時間怨聲嘆氣,因為還有無數的競爭博弈在等著他們.
1900/1/1 0:00:00要點: 一個新的mev-boost功能允許驗證者通過在本地構建低MEV塊同時仍然外包高MEV塊的構建來最大化以太坊的審查阻力。使用此功能會帶來機會成本——恢復力的代價.
1900/1/1 0:00:00與民主黨的千絲萬縷 FTX成立于2019年,并以某種方式迅速成為加密貨幣領域的大腕之一。但沒有人記得創始人SBF是從哪里來的,以及他是如何迅速晉升到這樣一個職位的.
1900/1/1 0:00:00


