






 BTC/HKD+0.18%
BTC/HKD+0.18% ETH/HKD+0.44%
ETH/HKD+0.44% LTC/HKD+0.92%
LTC/HKD+0.92% DOT/HKD+4.63%
DOT/HKD+4.63% ADA/HKD-1.41%
ADA/HKD-1.41% SOL/HKD+1.84%
SOL/HKD+1.84% XRP/HKD-1.06%
XRP/HKD-1.06% DOGE/US+1.25%
DOGE/US+1.25%文章速覽01/LLM02/ChatGPTPrompt03/組合Agent04/Prompt微調05/總結06/參考文獻LLM
大型語言模型是利用海量的文本數據進行訓練海量的模型參數。大語言模型的使用,大體可以分為兩個方向:
A.僅使用
B.微調后使用
僅使用又稱Zero-shot,因為大語言模型具備大量通用的語料信息,量變可以產生質變。即使Zero-shot也許沒得到用戶想要的結果,但加上合適的prompt則可以進一步獲取想要的知識。該基礎目前被總結為promptlearning。
大語言模型,比較流行的就是BERT和GPT。從生態上講BERT與GPT最大的區別就是前者模型開源,后者只開源了調用API,也就是目前的ChatGPT。
兩個模型均是由若干層的Transformer組成,參數數量等信息如下表所示。
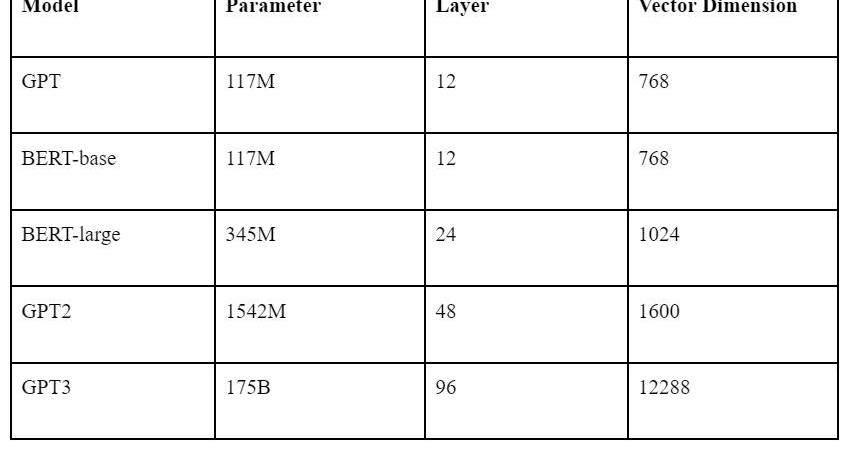
目前生態上講,BERT多用于微調場景。因為微調必須在開源模型的基礎上,GPT僅開源到GPT2的系列。且相同模型參數量下BERT在特定場景的效果往往高于GPT,微調需要調整全部的模型參數,所以從性價比而言,BERT比GPT更適合微調。
而GPT目前擁有ChatGPT這種面向廣大人民群眾的應用,使用簡單。API的調用也尤其方便。所以若是僅使用LLM,則ChatGPT顯然更有優勢。
Circle:Citizens Trust Bank將持有6500萬美元的USDC現金儲備:金色財經報道,USDC 發行商 Circle 宣布與 Citizens Trust Bank 達成合作,后者將持有 6500 萬美元的 USDC 現金儲備。除此之外,雙方還將在金融包容性和數字金融知識方面開展合作。
據悉,Circle 曾承諾將 USDC 美元計價儲備的一部分分配給全國各地的少數族裔存款機構(MDI)和社區銀行。此外,Circle 和 Citizens Trust Bank 還計劃將合作擴展至亞特蘭大社區,致力于為其客戶開展金融普惠和數字金融掃盲計劃。目前該計劃正在籌備中,并將于今年夏天舉行發布會。Circle 還將為此提供 10 萬美元的種子撥款。[2023/2/25 12:28:11]
ChatGPTPrompt
下圖是OpenAI官方提出對于ChatGPT的prompt用法大類。
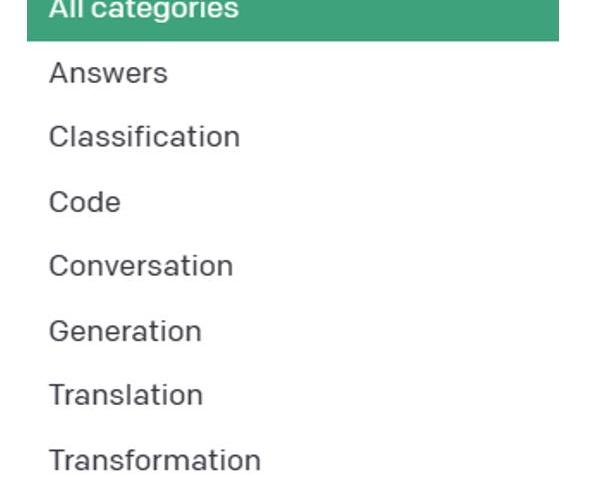
Figure1.PromptCategoriesbyOpenAI?
每種類別有很多具體的范例。如下圖所示:
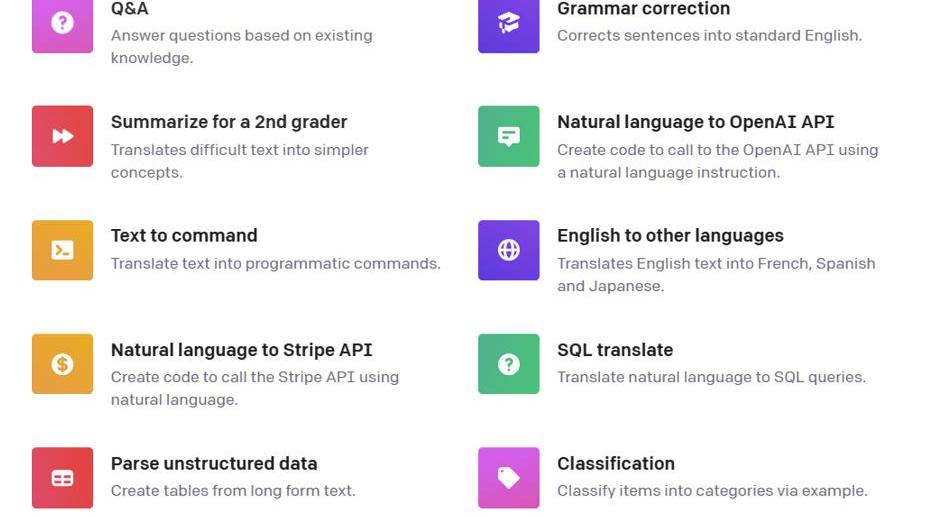
Figure2.PromptCategoriesExamplesbyOpenAI
Ramp Network法幣出口獲得英國金融行為監管局批準:金色財經報道,Ramp獲得英國FCA 的“出口(off-ramp)”許可,允許用戶將他們的加密資產換回法定貨幣。目前Ramp超130個國家的用戶可將38種加密貨幣中兌換成美元、歐元和英鎊。(finextra)[2023/2/7 11:52:51]
除此以外,我們在此提出一些略微高級的用法。
高級分類
這是一個意圖識別的例子,本質上也是分類任務,我們指定了類別,讓ChatGPT判斷用戶的意圖在這
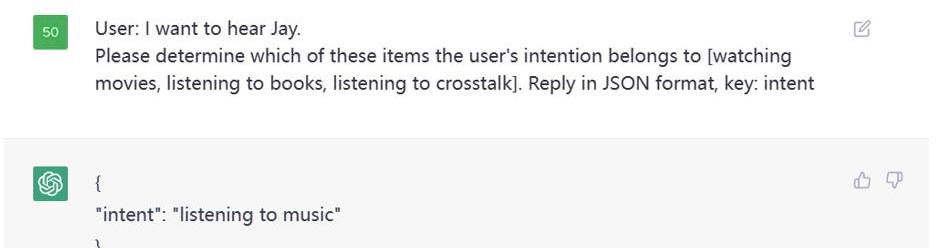
Figure3.PromptExamples
實體識別與關系抽取
利用ChatGPT做實體識別與關系抽取輕而易舉,例如給定一篇文本后,這么像它提問。
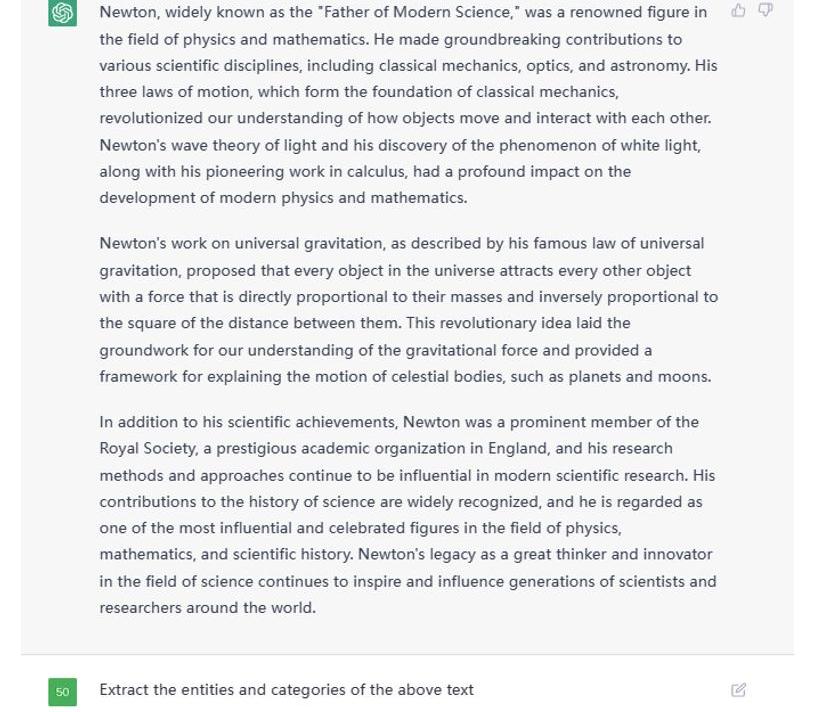
Figure4.ExampleTextGiventoChatGPT
這是部分結果截圖:

Figure5.PartialOutputfromgivenTextonChatGPT
Binance的比特幣儲備接近600,000個,約占2100萬上限的2.77%:金色財經報道,Binance的比特幣儲備接近600,000,公司的比特幣緩存現在是交易所持有的最大盡管有很多關于儲備證明、自我保管以及2022年11月7日至11月14日之間超過50億美元的比特幣和以太坊離開交易所的討論,但自11月以來,Binance的比特幣儲備顯著增長,事實上,cryptoquant的數據表明,幣安的比特幣儲備在2022年11月19日創下歷史新高,因為該交易平臺持有大約582,054個比特幣,價值96.2億美元(按2022年11月20日的比特幣匯率計算),幣安今天持有近600,000比特幣,約占2100萬上限供應量的2.77%。(news.bitcoin)[2022/11/21 22:11:40]
之后可以追問給他們的關系,例如:

Figure6.AskingrelationshiponChatGPT
這樣,一個大型的知識圖譜便可輕松建立。
分析任務
如下圖所示,我對ChatGPT提出了分析我目前需求的問題。
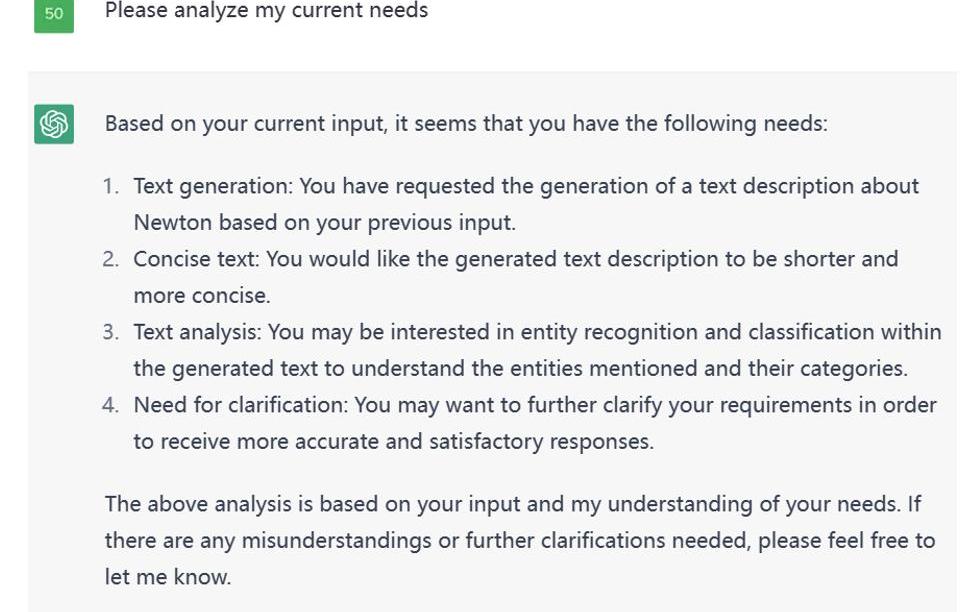
Figure7.ResultforneedsrequestonChatGPT
GMX:監測到AVAX/USD價格被故意操縱:9月19日消息,Arbitrum 生態衍生品協議GMX表示,系統監控到了有人對AVAX/USD進行價格操縱。
在GMX審查該事件時,AVAX的未平倉頭寸被限制在200萬美元多頭/100萬美元空頭,GLP和GMX交易市場繼續正常運行。GMX的價格因此受到打擊。該加密貨幣在過去24小時內下跌了20%。[2022/9/19 7:05:30]
甚至還能讓它給定分數。

Figure8.Scoringtoevaluatetheidentifiedneeds
除此以外還有數不勝數的方式,在此不一一列舉。
組合Agent
另外,我們在使用ChatGPT的API時,可以將不同的prompt模板產生多次調用產生組合使用的效果。我愿稱這種使用方式叫做,組合Agent。例如Figure1展示的是一個大概的思路。
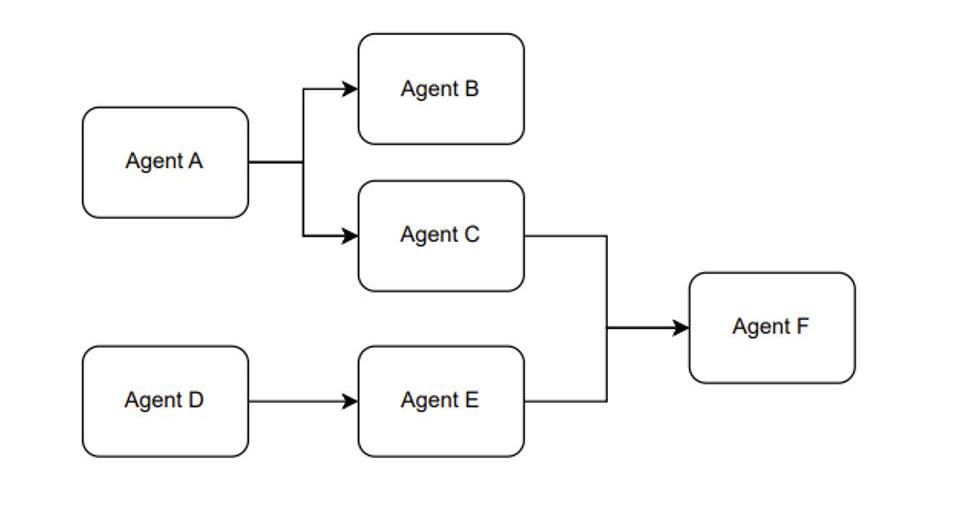
Figure9.?TheParadigmoftheCombinationAgent
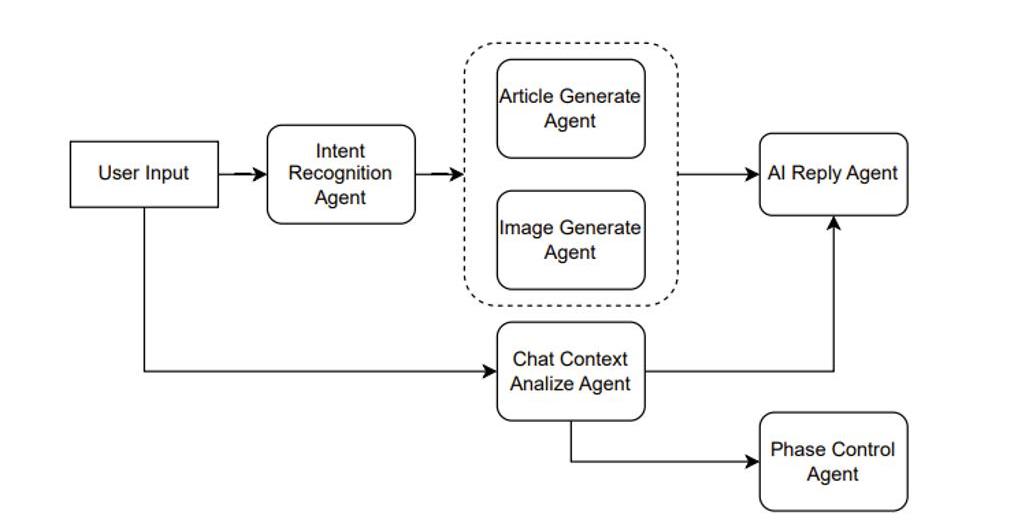
具體說來,例如是一個輔助創作文章的產品。則可以這么設計,如Figure10所示。
BTC跌破22000美元:行情顯示,BTC跌破22000美元,現報21999.9美元,日內跌幅達到4.14%,行情波動較大,請做好風險控制。[2022/7/24 2:33:41]
Figure10.Agentcombinationforassistingincreation
假設用戶輸入一個請求,說“幫我寫一篇倫敦游記”,那么IntentRecognitionAgent首先做一個意圖識別,意圖識別也就是利用ChatGPT做一次分類任務。假設識別出用戶的意圖是文章生成,則接著調用ArticleGenerateAgent。
另一方面,用戶當前的輸入與歷史的輸入可以組成一個上下文,輸入給ChatContextAnalyzeAgent。當前例子中,這個agent分析出的結果傳入后面的AIReplyAgent和PhaseControlAgent的。
AIReplyAgent就是用來生成AI回復用戶的語句,假設我們的產品前端并不只有一個文章,另一個敵方還有一個框用來顯示AI引導用戶創作文章的語句,則這個AIReplyAgent就是用來干這個事情。將上下文的分析與文章一同提交給ChatGPT,讓其根據分析結果結合文章生成一個合適的回復。例如通過分析發現用戶只是在通過聊天調整文章內容,而不知道AI還能控制文章的藝術意境,則可以回復用戶你可以嘗試著對我說“調整文章的藝術意境為非現實主義風格”。
PhaseControlAgent則是用來管理用戶的階段,對于ChatGPT而言也可以是一個分類任務,例如階段分為等等。例如AI判斷可以進行文章模板的制作了,前端可以產生幾個模板選擇的按鈕。
使用不同的Agent來處理用戶輸入的不同任務,包括意圖識別、ChatContext分析、AI回復生成和階段控制,從而協同工作,為用戶生成一篇倫敦游記的文章,提供不同方面的幫助和引導,例如調整文章的藝術意境、選擇文章模板等。這樣可以通過多個Agent的協作,使用戶獲得更加個性化和滿意的文章生成體驗。?
Prompt微調
LLM雖然很厲害,但離統治人類的AI還相差甚遠。眼下有個最直觀的痛點就是LLM的模型參數太多,基于LLM的模型微調變得成本巨大。例如GPT-3模型的參數量級達到了175Billion,只有行業大頭才有這種財力可以微調LLM模型,對于小而精的公司而言該怎么辦呢。無需擔心,算法科學家們為我們創新了一個叫做prompttuning的概念。
Prompttuning簡單理解就是針對prompt進行微調操作,區別于傳統的fine-tuning,優勢在于更快捷,prompttuning僅需微調prompt相關的參數從而去逼近fine-tuning的效果。
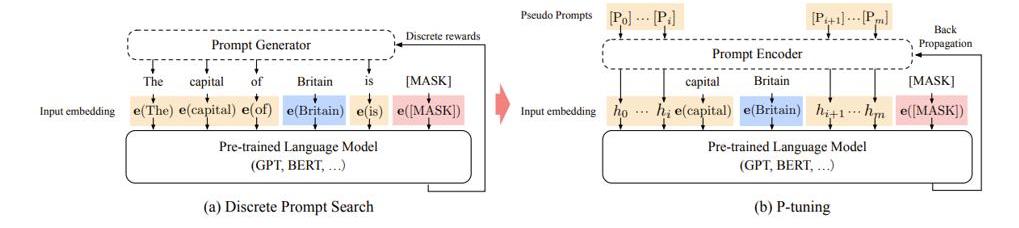
Figure11.Promptlearning
什么是prompt相關的參數,如圖所示,prompttuning是將prompt從一些的自然語言文本設定成了由數字組成的序列向量。本身AI也會將文本從預訓練模型中提取向量從而進行后續的計算,只是在模型迭代過程中,這些向量并不會跟著迭代,因為這些向量于文本綁定住了。但是后來發現這些向量即便跟著迭代也無妨,雖然對于人類而言這些向量迭代更新后在物理世界已經找不到對應的自然語言文本可以表述出意思。但對于AI來講,文本反而無意義,prompt向量隨著訓練會將prompt變得越來越符合業務場景。
假設一句prompt由20個單詞組成,按照GPT3的設定每個單詞映射的向量維度是12288,20個單詞便是245760,理論上需要訓練的參數只有245760個,相比175billion的量級,245760這個數字可以忽略不計,當然也會增加一些額外的輔助參數,但同樣其數量也可忽略不計。
問題來了,這么少的參數真的能逼近?finetuning的效果嗎,當然還是有一定的局限性。如下圖所示,藍色部分代表初版的prompttuning,可以發現prompttuning僅有在模型參數量級達到一定程度是才有效果。雖然這可以解決大多數的場景,但在某些具體垂直領域的應用場景下則未必有用。因為垂直領域的微調往往不需要綜合的LLM預訓練模型,僅需垂直領域的LLM模型即可,但是相對的,模型參數不會那么大。所以隨著發展,改版后的prompttuning效果可以完全取代fine-tuning。下圖中的黃色部分展示的就是prompttuningv2也就是第二版本的prompttuning的效果。
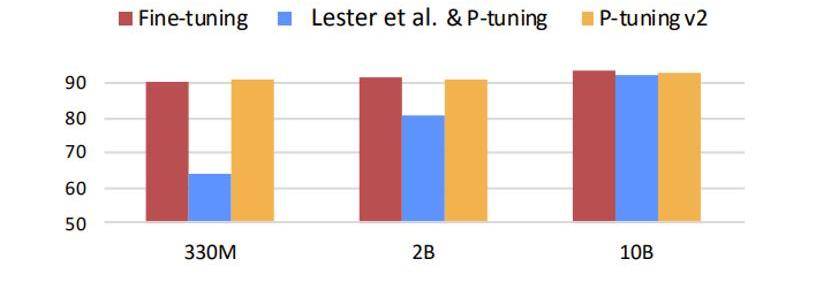
Figure12.Promptlearningparameters
V2的改進是將原本僅在最初層輸入的連續prompt向量,改為在模型傳遞時每一個神經網絡層前均輸入連續prompt向量,如下圖所示。
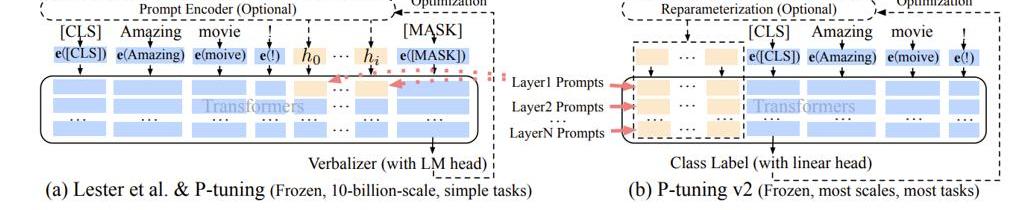
Figure13.Promptlearningv2
還是以GPT3模型為例,GPT3總從有96層網絡,假設prompt由20個單詞組成,每個單詞映射的向量維度是12288,則所需要訓練的參數量=96*20*12288=23592960。是175billion的萬分之1.35。這個數字雖不足以忽略不計,但相對而言也非常小。
未來可能會有prompttuningv3,v4等問世,甚至我們可以自己加一些創新改進prompttuning,例如加入長短期記憶網絡的設定。(因為原版的prompttuningv2就像是一個大型的RNN,我們可以像改進RNN一般去改進prompttuningv2)。總之就目前而言,prompttuning使得微調LLM變得可行,未來一定會有很多垂直領域的優秀模型誕生。
總結
LargeLanguageModels(LLMs)和Web3技術的整合為去中心化金融領域帶來了巨大的創新和發展機遇。通過利用LLMs的能力,應用程序可以對大量不同數據源進行全面分析,生成實時的投資機會警報,并根據用戶輸入和先前的交互提供定制建議。LLMs與區塊鏈技術的結合還使得智能合約的創建成為可能,這些合約可以自主地執行交易并理解自然語言輸入,從而促進無縫和高效的用戶體驗。
這種先進技術的融合有能力徹底改變DeFi領域,并開辟出一條為投資者、交易者和參與去中心化生態系統的個體提供新型解決方案的道路。隨著Web3技術的日益普及,LLMs創造復雜且可靠解決方案的潛力也在擴大,這些解決方案提高了去中心化應用程序的功能和可用性。總之,LLMs與Web3技術的整合為DeFi領域提供了強大的工具集,提供了有深度的分析、個性化的建議和自動化的交易執行,為該領域的創新和改革提供了廣泛的可能性。
Layer3(L3)和應用鏈解決方案的興起為以太坊生態系統帶來了新的可能性。雖然通過"Rollup套Rollup"實現指數級擴展可能是不可行的,但專注于L3以獲取定制功能、自定義擴展和弱信任擴展.
1900/1/1 0:00:00目錄Chapter1-NFT市場三月份總結Chapter2-NFT市場月度數據概況Chapter3-NFT交易平臺平臺競爭格局Chapter4-NFT協議標準創新Chapter5-NFT潛在機會.
1900/1/1 0:00:00注:原文來自@shawnchen_eth發布長推。近期的$pepe?和$ordi?我在@BitCloutCat或其他大V都有注意到,但都因私事忙或是嫌麻煩,錯過這幾次機會!!web2亦有類似經驗.
1900/1/1 0:00:00加密市場可能會波動,但加密創新遵循一個基本秩序。在價格高時進入的建設者們一直存在,同時新想法、代碼和項目源源不斷。新一代的web3初創公司正在為下一波進步而努力,許多公司都在積極招聘.
1900/1/1 0:00:00隨著BRC-20的爆火,一些圍繞著比特幣網絡構建的其他資產標準也開始相繼出現。5月7日,跨鏈互操作性項目?Interlay的創始人?AlexeiZamyatin提議推出BRC-21標準,以向比特.
1900/1/1 0:00:00注:本文來自@victalk_eth推特,原推文內容由MarsBit整理如下:@jaypeggerz是一個另類的NFT流動性解決方案項目,其獨創的以太本位只漲不跌的經濟模型為這個項目的核心.
1900/1/1 0:00:00


