






 BTC/HKD+0.42%
BTC/HKD+0.42% ETH/HKD+0.69%
ETH/HKD+0.69% LTC/HKD+1.82%
LTC/HKD+1.82% DOT/HKD+5.4%
DOT/HKD+5.4% ADA/HKD-0.76%
ADA/HKD-0.76% SOL/HKD+2.7%
SOL/HKD+2.7% XRP/HKD-0.49%
XRP/HKD-0.49% DOGE/US+1.67%
DOGE/US+1.67%作者:肖仰華,系復旦大學教授、上海市數據科學重點實驗室主任
來源:澎湃新聞
·通用人工智能是人類歷史上第一次關于智能本身的革命,是一種元革命,是歷次某個技術革命難以比擬的。大模型的誕生宣告了整個人工智能進入全新的重工業時代。
·反觀國內大模型產業,從表象上看是熱鬧非凡、模型林立,但是剝開外殼,從內里看是發展無序與內核空虛,不免讓人擔憂。大模型產業發展應該極力避免再走大煉鋼鐵的舊路,需要統一規劃,合作協同,立法保障、有序發展、健康發展。
自2022年12月OpenAI發布ChatGPT以來,國內外人工智能產業界掀起了軒然大波,一場以生成式人工智能為核心的通用人工智能產業風暴席卷而來。國內相關研發機構與企業紛紛跟進,投入巨大資源發展類ChatGPT的各種大模型與產品。據不完全統計,在ChatGPT發布后的短短4個月時間里,已經有至少30個國內研發機構與企業在ChatGPT發布之后紛紛推出自己品牌的大模型與相關產品。一時間,整個產業圈熱鬧紛呈、爭先恐后,“類ChatGPT”漫天飛舞,“國內首發”比比皆是,資本市場聞風而動、風起云涌。然而,越是表面熱鬧,越容易掩蓋內里的空虛;越是噱頭不斷,越需要冷靜的思考。熱鬧景象背后是一系列令人擔心的問題,只有不斷發現問題、總結問題、解決問題,才有可能保障這個產業健康有序的發展。
作為親身經歷者,我們正在見證著由通用人工智能所帶來的前所未有的技術革命。通用人工智能是人類歷史上第一次關于智能本身的革命。歷次技術突破只是人類智能的產物,而唯獨通用人工智能是‘智能’本身的革命。我們有可能在人類歷史上首次見證一個全新智能物種的出現,它具備人類水平的智能,甚至有可能超越人類的智能。這樣一種關乎智能本身的革命是一種元革命,是歷次某個技術革命難以比擬的。我們見證了生成式語言模型,以ChatGPT為代表已經席卷全球,兩個月之內,吸引了數億的用戶;我們見證了Midjourney以假亂真的文圖生成;我們甚至還見證了谷歌最近發布的PaLM-E,第一個多模態的具身的大規模語言模型,它能夠用語言模型操控機械臂并完成復雜的操控任務。機器已經從單純的模擬人類大腦的智能逐步發展到與身體相結合的智能,這將引發機器智能持續的連鎖的革命。如果機器智能僅限于實現人類的大腦,即便是超級大腦,其作用僅限于邏輯世界,起到輔助決策作用,但是一個武裝了身體的大腦,就完全具備對物理世界進行肆意改造的可能。出于保障人類安全的考慮,必須足夠重視通用人工智能,極力規范與控制其發展。
這一波通用人工智能產業浪潮始發于大規模生成式語言模型,也就是人們常說的大模型。最近幾個月,國內人工智能各大廠商紛紛發布自己的大模型,可以說是熱點紛呈。以往人類歷史重大事件的發生一般會用年、月來作為度量單位,從來沒有像今天這樣,需要用天為單位記錄某個變革事件。這一現象本身就已意味深遠,人類社會可能已經經歷了未來學家們曾預言過的奇點時刻,回過頭來看可能是人類歷史發展史上非常重大的歷史事件。最近幾個月,我們也看到了諸多的產業界巨頭紛紛布局自己的大模型戰略,可以說“不入局就出局”已經成為人工智能企業發展的基本態勢。
觀點:Coinbase成功上市或將促使韓國加密交易平臺采取類似行動:韓國分析師仍在繼續討論韓國加密貨幣交易所Upbit運營商Dunamu的市值,因為有關該公司尋求在美股上市的傳言越來越多。業內人士聲稱,Dunamu的價值對于國內交易所來說高得令人望而卻步,許多業內人士聲稱,對coinbase式的納斯達克上市的興趣是真實存在的。該公司一直對猜測保持沉默。根據韓聯社的說法,如果將Coinbase的“凈利潤/市值資本比率”應用于Dunamu,則后者的估計價值將達到“約114億美元”。而韓聯社還援引KB證券和三星證券研究人員的計算稱,Dunamu今年的營業利潤最高可達9億至9.88億美元,這意味著根據研究人員的計算,Dunamu的估值可能高達179億美元。分析人士還表示,Upbit最大的加密交易所競爭對手Bithumb也可能是一個很好的上市候選者。盡管如此,專家們一致認為,Coinbase的上市可能會促使韓國的交易平臺采取行動。(Cryptonews )[2021/4/17 20:29:54]
大模型的誕生宣告了整個人工智能進入全新的重工業時代。回顧人類歷史上的歷次技術革命,多始于初始的相對低級的“手工作坊”模式,經過漫長的發展周期,最終形成了成熟的重工業發展模式。比如紡織業,早期的紡織業是典型的家家戶戶都可以從事的手工作坊模式,為了進一步提高質量與規模,最終演變成為重工業化的生產模式。人工智能產業發展也正在經歷這樣的模式轉變。傳統的人工智能產業發展多采取場景與任務特異的研發與產品模式,需要精心的設計、審慎的論證,需要領域定制與客戶適配,很難形成通用的產品或平臺。但是,伴隨著AGI的發展,使用大模型作為統一底座,再經領域知識注入、任務指令調優、人類價值對齊,就可以形成解決領域中特定任務的求解能力,并具備一定的倫理與價值安全性。這種統一架構、統一范式是人工智能技術規模化的強勁推進器。這樣一種新的生產模式完全是一種重工業化的生產模式。我們要花大量的設備、人力、數據去煉制一個重型的裝備,這就是起著底座作用的大模型。底座大模型作為智能的通用平臺賦能各種各樣的應用。
重工業化的人工智能有三個鮮明的特征:大模型、大算力和大數據。
大模型的名稱本身表達的就是大規模參數化的模型。作為人工智能最為重要的分支之一,機器學習,旨在讓機器模擬人類從經驗進行學習的能力,在過去二十多年獲得了長足的進步,帶動了整個人工智能產業的發展。機器學習經歷了從傳統統計模型到深度神經網絡、從單一學習方式到綜合學習方式、從有監督到無監督等一系列轉變,最終集中地呈現在從小模型到大模型的演變。為什么模型會越來越大?這本身就是個值得深入思考與嚴肅回答的問題。20世紀以來,現代科學與人文經歷上百年的充分發展之后,變革了人類對于世界的理解,世界圖景逐漸從確定性轉變為不確定性、認知方式從分析轉變為綜合、建模范式從線性轉變為非線性。這些轉變為人工智能、機器學習的進步與發展奠定了必要的思想基礎。近十年,數據的充分準備、算力的持續發展,最終為大模型的到來做好了最后的嫁妝。可以說大模型的到來是技術發展的必然。
觀點:Coinbase上市成為加密貨幣行業的分水嶺:Coinbase 即將在納斯達克直接上市,投資者稱贊這是加密貨幣行業的一個分水嶺時刻。他們相信通脹即將到來,希望分散投資組合。
Wedbush Securities分析師Dan Ives表示,Coinbase的上市將成為華爾街關注的焦點,以判斷投資者的興趣。加密交易平臺Luno首席執行官Swanepoel表示,Coinbase上市將表明這個行業規模在擴大,增速在加快。 (金十)[2021/4/14 20:20:16]
重工業化的人工智能的第二個鮮明特點是大算力。隨著大模型參數量的持續增長,大模型對于算力的需求越來越迫切。算力已經成為大模型玩家的準入門檻,已經成為制約大模型發展的主要瓶頸。如果說模型和數據都是虛擬化、數字化的軟資源,那么算力則是實體化、現實性的硬實力。數字世界的發展從本質上來講是建立在實體世界的基礎之上的。實體決定數字是二者的基本關系。數字經濟的發展與競爭歸根結底將是算力的競爭。算力就是國家競爭力,就是企業競爭力。幾乎所有的大模型玩家都缺算力,大家要么在買算力,要么在買算力的路上。大模型行業生態最穩定的贏家必然是算力供應方。夯實算力基礎,實現算力自主可控,具有全局戰略意義。
重工業化的人工智能的第三個鮮明特點是大數據。大模型需要數據作為原料。過去的大數據時代為大模型的發展奠定了必要的數據基礎。大數據時代的發展為人工智能時代大模型的煉制準備了充分的煉制原料。大模型也成為了大數據價值變現的重要方式之一。傳統的數據挖掘與分析方法需要極大的專家成本,需要專家標注樣本、設計特征、構建模型、評測評價,才能捕捉大數據的統計規律、構建有效的預測模型,進而實現數據驅動的價值變現。很多甲方客戶不單單要出資,還需要積極投入巨大精力輸入行業知識。可以說傳統大數據的價值變現之路是艱難的,是成本高昂的。而今天,大模型無疑成為了大數據價值變現最有效的方式之一,使得用戶不再需要重度參與就能享受技術價值。躺在若干服務器上“沉睡”的大數據,經過必要的清洗與加工就可丟進大模型的冶煉爐里。最終通過煉制出的大模型實現行業統一賦能。大模型為大數據的價值變現趟出了一條“端到端”的道路,加快了大數據的價值變現進程,為大數據價值變現提供了一條新路徑。基于大模型的大數據價值變現給我國數字化轉型帶來全新契機。
除了以上這三個特征或者要素之外,我想強調第四個十分重要但是還未引起足夠重視的因素,那就是工藝過程。工藝過程是所有重工業發展的至關重要的因素之一。傳統的制造業給過我們很多有益的啟發。我國是制造業大國,但在某些領域我們的制造水平仍然有限,限制其發展水平的往往不是原料、不是設備,而是工藝過程。也就是說,相同的生產原料與設備,經過不同的工藝過程會得到不同質量的產品。重工業的高質量發展離不開先進工藝。當前我國大模型產業發展在數據方面是有優勢的,在算力方面是有基礎的,在模型方面也不存在什么秘密,唯獨大模型煉制的先進工藝過程是我們所缺乏的,是短期之內難以跟上或者超越的,是需要付出巨大代價進行摸索的。幾乎所有核心部件的關鍵工藝過程,比如芯片封裝,企業都是束之高閣視作最高機密。企業的核心競爭力往往就是成熟的、先進的工藝過程。OpenAI真正秘而不宣的核心關鍵就是它的工藝過程,包括數據配方、數據清洗、參數設置、流程設計、質量控制等等,從根本上決定了大模型的效果。所以任何重工業,包括人工智能,一旦進入重工業模式,都要尤為關注其工藝過程。
觀點:新基建過程中區塊鏈、大數據等關鍵核心技術會層出不窮:8月6日消息,南京郵電大學物聯網研究院院長朱洪波表示,新一代基礎設施面向智能化生產服務需求,必須是全新的、顛覆性的。5G只是一個起點,而不是終點。在新基建過程中,會有各種各樣的關鍵核心技術像雨后春筍般層出不窮,比如邊緣計算、人工智能、區塊鏈、大數據等,未來可以利用這些技術去解決智能化生產服務的問題。(新華日報)[2020/8/6]
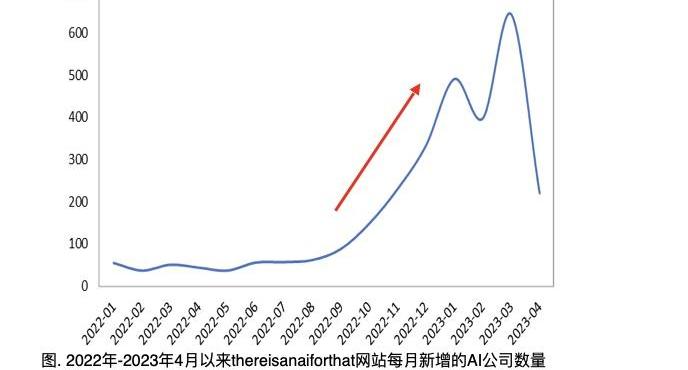
放眼世界,我們看到西方世界圍繞著大模型已經初步形成相對完整的產業生態。根據http://theresanaiforthat.com統計,截至2023年5月5日,國際上涌現出了近4000家AI創新企業。自從2022年9月以來,新的AI企業的誕生數量隨著時間呈指數增長。這些創新企業有相當數量是圍繞大模型周邊產品的生態企業。這些有如雨后春筍般涌現的生態企業,多圍繞著大模型落地的最后一公里中的應用痛點問題進行市場定位,解決特定場景的大模型落地痛點問題,解決大模型在行業應用中的痛點問題。可以說大模型對于整個生態發展的引領與帶動作用是十分巨大的。生態企業的發展進一步反哺大模型自身,周邊與核心雙向拉通、連鎖反應,勢必帶動整個人工智能行業的發展。可以說ChatGPT的出現是人工智能產業發展的分水嶺。ChatGPT之前,人工智能產業處于手工作坊階段,需要經歷漫長的原始積累與技術儲備,不斷消磨人們的耐心與觀望。ChatGPT之后,人工智能產業進入了重工業時代,迎來了快速發展、規模化聚集的新階段,躬身入局、時不我待或許是當前從業者心態的最真實寫照。此刻,以全部的熱情與經歷投身于人工智能輝煌發展的新時代都是不過分的。
反觀國內大模型產業,從表象上看是熱鬧非凡、模型林立,但是剝開外殼,從內里看是發展無序與內核空虛,不免讓人擔憂。一方面,幾乎所有國內人工智能產業的重要企業與研發機構紛紛推出了自己的類ChatGPT大模型。這說明,大家都意識到了生成式大模型的重要意義,意識到了短板與落后,發奮圖強,奮力追趕。另一方面卻是大模型產業發展已經出現一些問題,包括同質化嚴重、數據生態不完善、算力掣肘、模型創新有限。當前的大模型產業發展很像上世紀50年代的“大煉鋼鐵”運動,轟轟烈烈的全民大煉鋼鐵運動造成了人力、物力、財力的極大浪費。不同的是當年的運動是自上而下,今天的運動是自下而上。大模型產業發展應該極力避免再走大煉鋼鐵的舊路,需要統一規劃,合作協同,立法保障、有序發展、健康發展。全民大煉模型的后果一定是大模型成為一場代價高昂的華麗的煙花秀。
首先,技術路線同質化嚴重。比如說很多機構都是基于StanfordAlpaca的工藝過程去做基座模型微調,并利用ChatGPT等當前相對廉價的API生成數據來喂養自己的大模型。同質化的技術路線導致同質化的大模型。如果大家去問一問國內的大模型“你是誰”,很多回答就是“我是ChatGPT”。雖然跟隨是戰略發展的必經階段,但是絕不能停留在這一階段,要盡快形成自己的特色與核心,才有可能最終形成超越或者特色。
觀點:比特幣耗電量與美國家用電器耗電量相差甚遠:在劍橋大學另類金融中心加密貨幣研究主管Apolline Blandin?的最新一集《On the Brink》播客中,他談到了礦工的盈利能力和比特幣網絡的能源消耗,以及它是否確實對環境產生了不利影響。Blandin指出,關于比特幣礦池及其能源消耗的觀點總是會引起兩極分化的觀點。能源消耗也已變得至關重要,并且對礦工的盈利能力和生存至關重要。Blandin還認為,“如果比特幣很費電,那么你要看看美國那些一直開著但不使用的家用電器所消耗的電量,然后您就會意識到這些設備可以為比特幣世界供電約4.6年”。(AMBCrypto)[2020/6/7]
其次,數據生態不完善。我國仍然要以優先發展中文大模型為主要目標。然而,中文大模型研發生態還存在很多問題。首先是中文數據規模與質量仍存在不足。有數據統計,在互聯網公開語料中,中文數據大概只占百分之一點幾。這極大地限制了中文大模型的效果。除了規模有限之外,中文數據的質量也存在問題。互聯網開放環境的中文語料數據,其質量遠不如深網或者企業內部的數據。然而中文數據中的這些問題本身也孕育著新的機遇。行業數據、企業數據通常較為優質,但大都是私域數據,不對外開放。如何充分利用這些私域數據激發中文大模型的潛在價值是發展中文大模型過程中值得深思的重要問題。我們已然欣喜地看到一些數據聯盟組織正在積極推動中文高質量數據的匯聚與清洗。總體而言,完善的數據生態需要大家的共同努力。
第三,算力掣肘。英偉達高端GPU對中國供應受限,例如:新型H100顯卡對我國禁運。我們的國產算力雖然也很爭氣,總體來言與國外算力仍有差距。這些差距表現在國產算力生態不完善、單核算力總體而言性能相對較弱、對16位浮點數運算等底層計算技術支持不完善等諸多方面。其中,盡快健全國產算力生態尤為重要。從硬件到軟件、從廠商到用戶,算力生態需要各種角色共同努力與積極營造,才能讓國產算力變得更可用、更易用。
第四,模型創新有限。我們現有的模型多依賴國外開源社區的模型實現,在Transformers結構基礎上進行微量創新,或是針對特定硬件和底層軟件的Transformers模型結構優化。如果開源社區的模型實現對我們限制,或者存在底層調用鏈安全隱患,都會對國產大模型產業帶來損耗。必須防患于未然,積極發展自主可控的中文大模型開源社區。
針對以上問題,我們應該如何應對呢?我們需要系統性地回應這個問題,需要從數據共享、算力協作、開源生態、人才培養、評測體系、成本控制、應用探索與技術研究等各方面推動大模型發展。
1.積極推動數據聯盟的建設,促進優質數據的共享與傳播。事實上我國在數據流通和交易方面,還是走在國際前列的。我們成立了很多數據交易中心、數據交易所。政策方面還有“數據二十條”來保障數據的規范化交易與開放。那么依托我國相對完善的數據交易體系,為大模型產業發展量身定制相應的數據聯盟與交易機制,就是個值得優先發展的思路。同時在數據交易的過程中,應該做好頂層統一規劃,規范數據格式。大模型發展對于統一規范的數據標準要求尤為迫切,比如統一的語料格式、統一的指令格式、統一的標注數據格式。數據的規范化可以極大地降低大模型的數據治理代價。
聲音 | 觀點:如果美國免除1.6萬億美元學生貸款 可能會導致比特幣飆升:美國民主黨總統候選人參議員Bernie Sanders和參議員Elizabeth Warren提出免除1.6萬億美元的學生貸款。從表面上看,該計劃將增加對手頭拮據的年輕人的支出,并促進經濟增長。但是許多金融專家認為,與學生貸款豁免相關的風險因素以及此類行動的合憲性,可能會導致經濟災難。BeInCrypto文章稱,這種存在經濟風險的舉措很可能會導致比特幣飆升。聯邦債務增加、美元崩潰以及對合同安全的擔憂將把投資者趕出更廣闊的市場,轉而投資比特幣等非政府投資。與其他投資不同,比特幣不是基于合同義務。取而代之的是,比特幣的網絡被構建為“無需信任”的環境,從而保護它不受政府控制。當市場由于政府干預而下跌時,比特幣可以繼續受到保護。有了這種保護,隨著投資者逃往避險資產,比特幣的價格可能會大幅上漲。盡管債務減免計劃可能會損害美國經濟,但比特幣所有者將看到可觀的投資回報。(BeInCrypto)[2020/2/3]
2.大力推動算力聯盟,促進優質算力共享與協作。對于大模型產業發展而言,當前算力呈現出分散與異構的顯著問題。在實際大模型研發中,GPU往往分散在不同機房、不同數據中心,有著不同的網絡架構,不同的權限歸屬,對大模型的分布式聯合訓練提出了較高要求。傳統超算中心往往存在多卡互聯帶寬不足的問題,制約了算力效能的發揮。迫切需要將傳統集群網絡升級為使用了多卡鏈接新技術的NVLINK、IB等網卡。同時需要加快推進大模型在異構網絡環境下的分布式訓練等關鍵技術的研究。對于國產算力,應制定相關政策鼓勵發展。國產算力總體而言可以走一條數量換質量、空間換時間的戰略。單卡能力不足則通過多卡來提升,以構建更大規模的顯卡集群。為顯卡設計超一般規格的顯存,以容納更大模型,避免模型切分,來加速模型訓練。大模型的算力發展也要考慮到我國算力網絡建設的整體發展戰略。
3.推動模型實現開源,完善國產大模型的開源生態。在圖像生成領域,既有Midjourney這樣的封閉的公司化運作的成功案例,也有開源社區自發維護和研究的StableDiffusion模型。且開源模型由于參與者眾多,結果更可控、應用場景更豐富、模型演變更迅速。圖文生成領域的發展對于大模型發展具有重要參考意義。唯有開源生態才能對抗以ChatGPT為代表的封閉生態。凝聚國內外一切有志于開源運動的力量形成開放的大模型技術社區,打造中文大模型統一底座,積極開展基于底座模型的各種應用實踐,充分發揮我國數據資源豐富、應用場景豐富的優勢,著力提升AGI的可控性、功能性,以應對來自OpenAI的挑戰。
4.創新培養方式,培育大模型產業人才。人才匱乏是當前制約大模型產業發展的關鍵問題之一。有業內人士預計:“國內能夠進行相關技術研發的人才應該不超過1000人,保守一點來說僅有兩三百號人”。客觀來講,AGI的到來速度是始料不及的。即便放眼全球,學術界與工業界都沒做好迎接準備。除了OpenAI和微軟等少數贏家之外,大部分企業和研發機構都是倉促應對AGI的挑戰。而人才培養最需要的恰是時間。短期之內是無法培養能夠從事大模型產業的專業人才。當前“煉鋼爐林立”唯一的正面作用在于培養一批有模型煉制經驗的專業人才。在大模型人才培養方面,尤為要注重跨學科、跨專業的復合型人才培養。不僅要培養涉及大模型訓練、調優、評測、應用等各個環節的專業技術人才,更要培養兼通行業知識的提示工程師,培養兼通人文社科背景的大模型評測與分析專家,培養兼通大模型技術與產品設計的產品經理。在大模型人才培養中要注重產學研聯動的育人體系。育人與產業的邊界日益模糊,做產品的過程也是培養人的過程,要在實戰中育人,要上馬能作戰,下馬能讀書。人工智能產業發展的極高速度對于傳統的育人與產業脫節的專業人才培養思路提出了全新挑戰。
5.建立大模型的診斷與評測體系,保障大模型產業健康發展。這是保障大模型健康發展的關鍵舉措,同時具有戰略意義。掌握話語權的關鍵在于眼光不能停留在只做運動員,更要積極投身于裁判員的事業之中。大模型的發展需要系統性的診斷與評測,大模型的認知能力、解決問題能力、價值觀、傾向、安全性等等需要進行全方位評測。同時要注重建立面向研發環節的診斷體系,需要建立大模型的效用指征體系,建立相應的度量機制,建立大模型的健康評價體系,識別大模型煉制工藝過程的關鍵因素,建立大模型的診斷與優化模型。從診斷與評測兩個視角,建立與健全大模型的診斷與評價體系,建立大模型的評測基準,是大模型產業發展所亟需的,是形成差異化發展路線的關鍵。
6.研究綠色可持續的大模型煉制與應用技術,降低大模型落地成本。大模型的成本問題也是大模型技術形成產業應用閉環的關鍵問題。大模型成本巨大,是限制其應用的關鍵因素。大模型的成本首先是訓練成本。雖然互聯網開放環境中存在大量語料,但是高質量語料相對匱乏。因此,大模型所需要的大數據、大語料,仍需付諸巨大的人工成本進行清洗。第二類成本是算力。目前主流算力是英偉達的A100或A800顯卡,千億參數模型至少都需要千張A800顯卡,一張A800約9萬元人民幣,再考慮配套設備成本,千億參數的硬件成本至少是上億人民幣。訓練過程中還存在一定的硬件故障,進一步加重此開銷。第三項成本是能源。有報道稱“大模型訓練成本中60%是電費”;知名計算機專家吳軍也曾說:“ChatGPT每訓練一次,相當于3000輛特斯拉電動汽車每輛跑20萬英里”。第四項成本是部署成本。相較于訓練,部署時的顯卡需求量可能更大,才可能應對極高的并發訪問量。國內早期公開的類ChatGPT模型常因為算力有限遭遇巨大的瞬時訪問量而系統崩塌。此外,還需要考慮大模型的維護成本。大模型的持續學習、可控編輯、安全防護、價值對齊等等仍需深入研究。綠色、可持續發展、低成本的大模型技術是大模型進一步落地過程中的關鍵問題。
7.積極探索大模型的應用模式,豐富大模型的應用場景。大模型的應用模式也仍然面臨著若干問題。ChatGPT比較好地實現了機器與人類的開放式對話,也就是閑聊。然而實際應用場景多需機器的復雜決策能力,比如故障排查、疾病診斷、投資決策,對于錯誤有著較低的容忍程度,需要豐富的專業知識、復雜的決策邏輯,需要具備宏觀態勢的研判能力、綜合任務的拆解能力、精細嚴密的規劃能力、復雜約束的取舍能力、未知事物的預見能力、不確定場景的推斷能力等。可以說,從開放閑聊到復雜決策仍有漫長的道路要走。大模型如何在千行百業復雜的商務決策中應用仍是有待探索的問題。我們不能只是盲目跟隨ChatGPT,要對其能做什么不能做什么有清醒認識。要在領域的復雜決策場景中形成核心競爭力,要重新奪回戰略競爭中的主動權。
8.持續研究大模型煉制與應用關鍵技術,完善大模型技術體系。大模型從煉制到應用仍存在很多技術問題需要解決。首先是大模型的數據治理問題,這是大模型煉制過程中的關鍵問題。訓練數據的有效清洗、偏見消除、隱私保護、數據配比、提示增強、領域適配等仍是大模型煉制的關鍵技術問題。其次是大模型的可控編輯問題,這是大模型應用的關鍵問題。如何實現大模型事實、知識與信念的可控編輯?此外,還包括大模型的高并發服務與低成本部署、大模型的推理優化,以及生成式大模型幻象問題。此外,一個長遠的研究目標是持續提升大模型的類人認知能力,比如提升大模型的長文本理解以及全局約束理解能力,提升大模型的高級認知能力,比如自省、自識、規劃、記憶等。另一個長遠研究目標在于大模型之間的有效協同。
最后我想圍繞大模型的產業發展,提出一些開放性問題供大家思考。
問題一:我們能否定義一條具備中國特色的大模型產業發展道路?大模型熱潮源自美國,我們除了要加速完成技術追趕之外,能否提出一條具有中國特色的大模型發展道路,以形成差異化的發展路線和競爭格局?特別地,對于上海的企業而言,我們能否提出一條具有上海特色的大模型發展之路?在通用人工智能時代,往往只有第一沒有第二。所以利用中國特色,比如通過舉國體制統籌資源共享,是形成競爭優勢的關鍵所在。
問題二:傳統的“先研發再產品”軟件系統研發模式是否能勝任大模型驅動的智能系統軟件?基于大模型的軟件系統目前呈現的態勢是:“先產品再研發”,或“邊產品邊研發”。從研發到應用的節奏顯著加快,甚至已經沒有了傳統意義上的研發環節了,“研發就是產品,產品就是研發”。因此,大模型的帶動下,會不會形成一種全新的產品化模式?我們如何做出變革以適應“產研一體化”的全新研發模式?這是未來產品化過程需要深思的問題。
問題三:如何統籌規劃大模型產業發展布局?當前國內的大模型研發處于各自為政的階段,總體處于跟隨階段,同質化產品多、特色創新不鮮明。而隨著大模型規模的持續增大,單一團隊和機構往往缺少足夠的數據資源與算力來完成大模型的煉制與優化。那么,我們如何破除當前大模型發展過程中小爐子林立的問題?如何有效地促進數據聯盟、算力聯盟甚至人才聯盟?政府、市場、企業、科研院所、高校在整個規劃布局中各自發揮怎樣的功能與作用?
問題四:大模型會對當前的消費者市場形成怎樣的影響?傳統ToC產品都是功能性的、面向專用領域及專用任務的。而當前的AI正在向通用人工智能方向突飛猛進,最近一些研究工作也讓大模型具備了全網信息檢索與應用接口調用的能力。大模型發展到今天就好比是一個全科醫生,什么都知道一些,但是一旦到了專業問題可能還是需要咨詢某一個專科醫生。換言之,大模型的入口功能顯著。入口的本質是用戶接入、交互與分流。這恰恰就是ChatGPT類產品最擅長的能力。那么,當前的很多互聯網專用功能性平臺是否會被這個全新的統一入口所取代而只剩下一個基于ChatGPT的統一門戶?每一次互聯網入口的變換都是互聯網行業的一次變革,ChatGPT類的通用聊天大模型是否會成為各類互聯網生活服務的統一入口?大模型時代的未來ToC產品的基本形態是否會發生變革?
問題五:大模型會對當前的企業端市場形成怎樣的影響?企業端市場也就是我們常說的ToB市場也將會因為ChatGPT的到來而迎來一場全新變革。如果與傳統的汽車制造業類比,大模型對于ToB市場的首要意義在智能引擎升級。ToB產品是建立在智能引擎基礎之上的,傳統數據驅動、知識驅動或者二者聯合驅動的智能引擎,將會被全新的大模型引擎所重塑。然而正如前文所述,大模型在領域復雜決策應用場景上仍然有明顯的短板與不足,尚達不到領域專家的能力。因此,我認為未來仍是以大模型為代表的數據驅動與領域知識圖譜為代表的知識驅動相結合的雙引擎驅動模式。由大模型實現領域專家的直覺決策,由知識圖譜實現領域專家的邏輯決策,唯有兩者結合才能復現領域專家解決問題的能力。如果與傳統的操作系統類比,大模型可以作為ToB產品的控制器。作為具有一定的領域通識能力的大模型,有能力勝任企業級智能系統的控制器,協調傳統的IT系統。然而在上述遠景產品研發中,我們仍然面臨許多具有挑戰性的問題。比如,如何協同領域知識與大模型?如何實現領域專家的直覺推理?如何實現領域知識與邏輯增強的大模型?如何實現領域大模型的安全與可控?
問題六:ChatGPT為何沒有誕生在中國?如何避免錯失下一個ChatGPT?我相信這兩個問題會觸發大家太多的思考與感嘆。我們鼓勵創新,卻極少能夠寬容失敗;我們尊重人才,卻又不斷建立條條框框;我們在太多無意義的事情上內卷與消耗,卻極少愿意停下腳步花上片刻欣賞路邊的芬芳;我們每個人都似陀螺一樣不停旋轉,每一步都是最優的理性決策,卻錯失了可貴的原始創新。久而久之,我們似乎習慣了追趕的驚心動魄,失去了引領的自信與大度。我們需要徹底反思我們的科研文化、科研生態,要避免在盲目追趕中變得麻木與沉淪,要更多地以閑暇與從容的姿態去思考去批判。
由ChatGPT所引發的通用人工智能產業變革,相信才剛剛開始。我們需要以更深切的思考、更扎實的實踐,牢牢抓住大模型以及其他通用認知智能技術給我國數字化轉型與高質量發展所帶來的全新機遇。同時,我們也要正視發展過程中出現的問題,積極規范與引導大模型產業的健康發展。大模型絕不是宣傳文案中的噱頭,也絕不能成為一場華麗的煙花秀,而要成為實實在在的能夠推動社會發展與進步的先進生產力。
撰寫:JoséMariaMacedo,DelphiVentures合伙人編譯:深潮TechFlowDelphiVentures合伙人JoséMariaMacedo盤點了一些Cosmos生態中的推.
1900/1/1 0:00:00據路透社消息,智利央行行長MarioMarcel周一表示,智利央行將在2022年初就可能推出數字貨幣的戰略做出決定,因為全球政策制定者都在尋求跟上加密貨幣的步伐.
1900/1/1 0:00:00由于BTC網絡并不支持圖靈完備的智能合約,因此自BTC誕生起,長期以來被用于點對點轉賬及價值儲存外的其他場景并不太多.
1900/1/1 0:00:00微博用戶“BCH愛好者BruceLee”通過微博表示,之前有說法ETH不應該算成是主流幣,而是應該和BTC一樣劃入第一梯隊.
1900/1/1 0:00:00據Cointelegraph報道,Piplsay進行的一項新民意調查發現,現在有41%的英國人認為投資加密貨幣的風險與股市一樣高.
1900/1/1 0:00:00日前,上海市人民檢察院第二分院依法提起公訴的一起利用虛擬貨幣非法買賣外匯案件獲得判決支持,法院以被告人王某構成非法經營罪判處其有期徒刑3年3個月,并處罰金人民幣3萬元.
1900/1/1 0:00:00


