






 BTC/HKD-1.18%
BTC/HKD-1.18% ETH/HKD-2.47%
ETH/HKD-2.47% LTC/HKD+0.58%
LTC/HKD+0.58% DOT/HKD-1.58%
DOT/HKD-1.58% ADA/HKD-2.04%
ADA/HKD-2.04% SOL/HKD-3.16%
SOL/HKD-3.16% XRP/HKD-2.86%
XRP/HKD-2.86% DOGE/US-1.18%
DOGE/US-1.18%本文主要來介紹NLP中的命名實體識別。命名實體識別與中文分詞、詞性標注一樣,也是NLP的一個基礎任務,是信息抽取、信息檢索、機器翻譯、問答系統等多種NLP技術不可或缺的一部分。其目的是:識別語料中的人名、地名、組織機構名等命名實體。
隨著命名實體數量的不斷增加,一般不可能在詞典中全部列出,由于命名實體的構成方法具有規律性,通常把對這些詞的識別在任務中進行獨立處理,稱之為命名實體識別。NER一般分為3大類和7小類。

1.中文命名實體識別的難點
各類命名實體的數量眾多。命名實體的構成規律復雜。比如人名的構成規則各有不同,中文人名識別又可以細分為中國人名識別、日本人名識別和音譯人名識別等;再比如機構名的組成方式,機構名的種類繁多,各有獨特的命名方式,用詞也相當廣泛,只有結尾用詞相對集中。嵌套情況復雜。一個命名實體經常和一些詞組合成一個嵌套的命名實體,人名中嵌套著地名,地名中也經常嵌套著人名。長度不確定。與其他類型的命名實體相比,長度和邊界難以確定,使得機構名更難識別。中國人名一般二到四字,常用地名一般二到四字,但是機構名長度變化范圍極大,少的只有兩個字簡稱,多的達到幾十個字的全稱。2命名實體識別方式
NuriFlex與AhnLab簽署NuriTopia項目諒解備忘錄:金色財經報道,NuriFlex Holdings Inc.宣布已與AhnLab Blockchain Company, Inc.簽署了一份諒解備忘錄。兩家公司將在多個地區就NuriTopia項目和Web3錢包展開合作。
NuriFlex Holdings參與設計和開發基于區塊鏈的虛擬世界生態系統,為不同的服務提供各種虛擬世界和數字體驗。該公司目前正在投資“元宇宙”項目,該項目預計將于今年啟動。[2023/5/19 15:12:38]
中文分詞中,主要有基于規則方法、基于統計方法和基于二者的混合方法。命名實體識別主要也包含這三種方法。
基于規則的命名實體識別:規則加詞典是早期命名實體識別中最行之有效的方式。依賴手工規則,結合命名實體庫,對每條規則進行權重賦值,然后通過實體與規則的相符情況來進行類型判斷。基于統計的命名實體識別:與分詞類似,目前主流的基于統計的命名實體識別方法有:隱馬爾可夫模型、最大熵模型、條件隨機場等。其主要思想是:基于人工標注的語料,將命名實體識別任務作為序列標注問題來解決。基于混合的命名實體識別:NLP并不完全是一個隨機過程,單獨使用基于統計的方法使狀態搜索空間非常龐大,必須借助規則知識提前進行過濾修剪處理。目前幾乎沒有單純使用統計模型而不使用規則知識的命名實體識別系統,在很多情況下是使用混合方法,結合規則和統計方法。序列標注方式是目前命名實體識別中的主流方法,下面重點介紹基于CRF條件隨機場的方法。
中小企業碳排放管理平臺Greenly獲2300萬美元融資:金色財經報道,近日,面向中小企業的碳排放管理平臺Greenly宣布獲2300萬美元A輪融資,Energy Impact Partners和XAnge Private Equity等公司共同參投。Greenly總部位于法國,通過其移動應用平臺幫助用戶測量碳足跡,鼓勵其降低碳排放。目前,Greenly的用戶已經超過400家,其中不乏安盛、雷諾等大型集團,并同時在法國和美國設立了辦事處。[2022/5/6 2:53:26]
3基于CRF的命名實體識別
條件隨機場的主要思想來源于HMM,也是一種用來標記和切分序列化數據的統計模型。不同的是,條件隨機場是在給定觀察的標記序列下,計算整個標記序列的聯合概率,而HMM是在給定當前狀態下,定義下一個狀態的分布。
Chainlist宣布將于4月3日停止服務:3月5日消息,EVM網絡聚合網站Chainlist發布公告稱,將于4月3日停止服務,源代碼是開源的,歡迎任何想繼續托管此服務的人。目前,ChainDirectory、chain-list等多個替代性網站已宣布上線。[2022/3/6 13:40:04]
條件隨機場的定義為:假設X=(X1,X2,X3,…,Xn)和Y=(Y1,Y2,Y3,…,Ym)是聯合隨機變量,若隨機變量Y構成一個無向圖G=(V,E)表示的馬爾可夫模型,則其條件概率分布P(Y|X)稱為條件隨機場,即:
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)
其中w~v表示無向圖G=(V,E)中與結點v有邊連接的所有節點,w≠v表示結點v以外的所有節點。
算法穩定幣Frax采用Chainlink替代Uniswap預言機:算法穩定幣協議Frax宣布將全部采用去中心化預言機Chainlink的解決方案作為價格來源,以替代此前采用的Uniswap TWAP價格。Frax表示,雖然Uniswap TWAP價格確實提供了一個完全鏈上的解決方案,但是市場覆蓋度不夠,并且是一個滯后的市場指標,可能會導致不準確,尤其是在價格波動的時期。[2021/8/21 22:28:19]
例如:對句子“我來到陶家村”進行標注,正確標注后的結果為:我/O來/O到/O陶/B家/M村/E。采用線性鏈CRF來進行解決,那么是其一種標注序列,也是是其一種標注選擇,類似的可選擇的標注序列有很多,在NER任務中就是在這么多的可選標注序列中,找出最靠譜的作為句子的標注。
神秘報告稱Chainlink項目為“欺詐”:金色財經報道,一家名為Zeus Capital的公司發布報告,將Chainlink標記為“欺詐”。 Zeus Capital聲稱自己是一家“資產管理和研究公司”,其網站的內容似乎很少,除了上述報告外幾乎沒有其他內容。聯系人詳細信息也很少,而且沒有列出地址、電話號碼和電子郵件地址。報告指控Chainlink項目使用了經典的拉高出貨把戲,依靠內幕信息交易,即將面臨崩潰。且Chainlink不計代價避免對主網上線日期做出承諾。報告稱,根據最新的SEC決定,LINK會被定義為證券。[2020/7/18]
那么我們要解決的問題就是要判斷標注序列是否靠譜。就剛才的兩種標注方法,顯然第一種比第二種更為準確,因為第二種將“陶”和“家”都作為地名首字標成了“B”,一個地名兩個首字符,顯然不合理。假如給每個標注序列打分,分值代表標注序列的靠譜程度,越高代表越靠譜,那么可以定一個規則,若在標注中出現連續兩個“B”結構的標注序列,則給它低分。連續“B”結構打低分就對應一條特征函數。在CRF中,定義一個特征函數集合,然后使用這個特征函數集合為標注序列進行打分,據此選出最靠譜的標注序列,該序列的分值是通過特征函數集合得出的。
在CRF中有兩種特征函數,分別為:轉移函數tk(yi-1,yi,i)和狀態函數sl(yi,X,i)。tk(yi-1,yi,i)依賴于當前和前一個位置,表示從標注序列中位置i-1的標記yi-1轉移到位置i上的標記yi的概率。sl(yi,X,i)依賴當前位置,表示標記序列在位置i上為標記yi的概率。通常特征函數取值為1或0,表示符不符合該條規則約束。
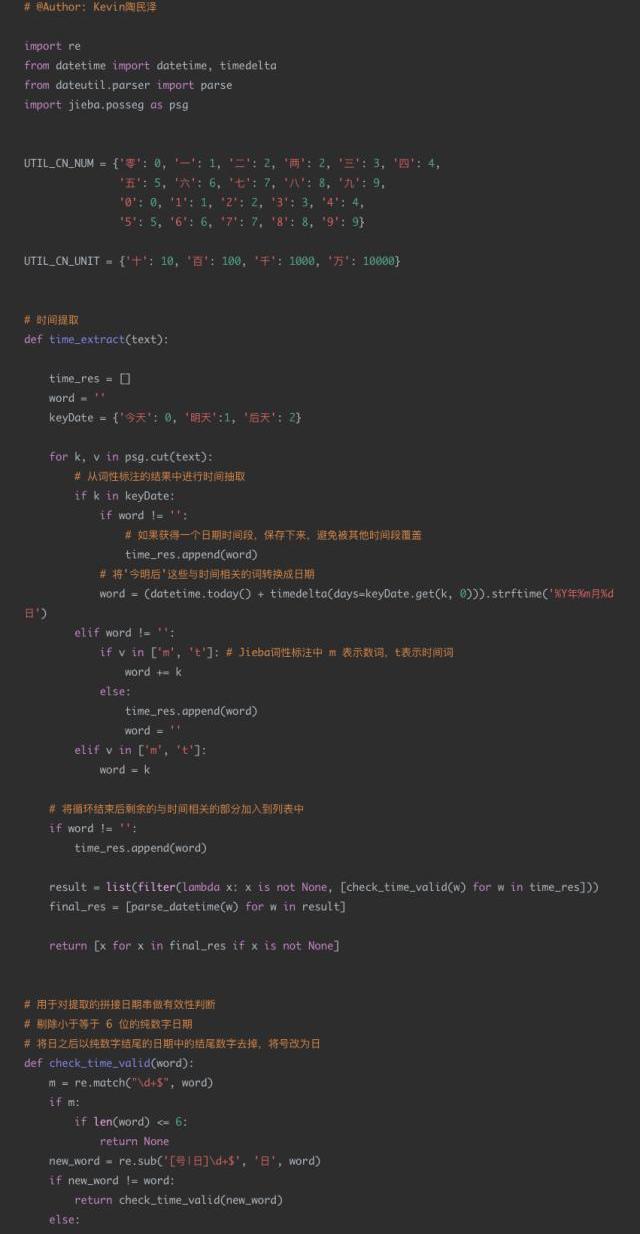
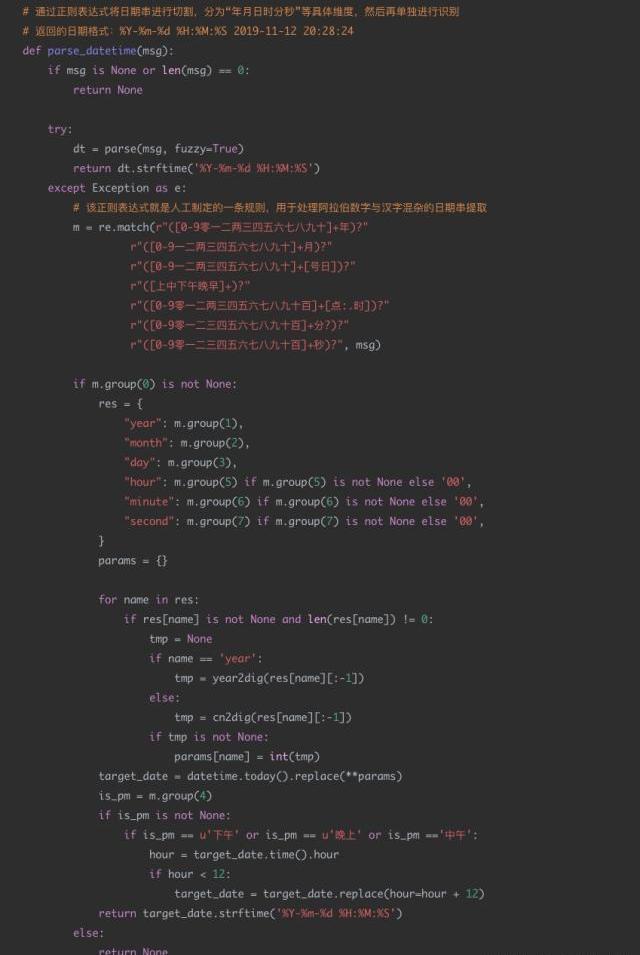
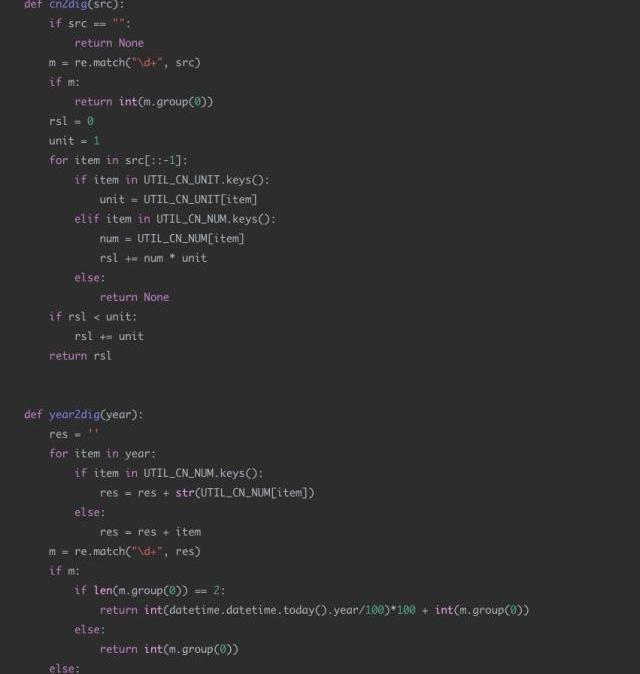
4日期識別代碼示例
應用場景:
現有一個智能外呼系統,由機器人撥打電話給客戶,通知客戶新股中簽情況,客戶與機器人進行對話。對話機器人根據用戶的語音進行解析,發覺用戶的需求,比如:新股中簽的時間,新股買入的時間等。通過asr技術將用戶的語音轉換成中文文本,然后由于asr的識別準確度問題,許多日期類的數據并不是嚴格的數字,比如會出現“十一月12日”“2019年11月”“20191112”“后天下午”等形式。
現在的需求是識別出每個請求文本中可能的日期信息,并將其轉換成統一的格式進行輸出。比如:“我打算今天或明天買入新股”,那么通過日期解析后,應該輸出為“2019-11-12”和“2019-11-13”。
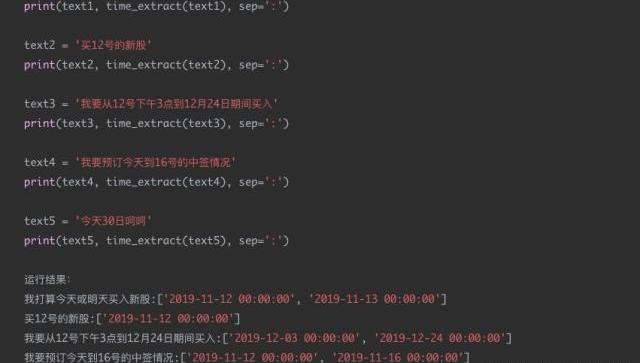
通過結果分析可以看到,text1text2text3text4結果還是相對較好的,對于text5這種規則覆蓋之外的場景,方法效果大大降低。
作者:KevinTao
知乎號:Kevin陶民澤
備注:轉載請注明出處。
如發現錯誤,歡迎留言指正。
最近,幣圈風頭都被FCOIN搶了去,一個交易所的興起到衰落確實牽動了很多韭菜的心,也再一次給投資敲響了警鐘。投資有風險,警鐘需長鳴.
1900/1/1 0:00:00新華財經北京1月6日電(郭興華)經歷了“雪崩”之后,2019年區塊鏈行業處于尋找新的起點再出發的二次創業階段。歷盡“浮華”,區塊鏈行業重新腳踏實地,穩步前進,技術創新將逐漸發揮重要作用.
1900/1/1 0:00:00寬容就是以寬廣和包容的心態,去面對人和事,寬容自身包含著謙遜。俗話說,滿招損,謙受益。寬容不但是一種與人和諧相處的品質,一種時代推崇的品德,更是吸納他人的優點、充實自我價值的良好道德品質.
1900/1/1 0:00:00琥珀是全球范圍內最受歡迎的寶石,不受國家、民族、地域的影響,而從全球的琥珀產地及種類來看,一般分為五大區,分別為波羅的海琥珀,緬甸琥珀,墨西哥藍珀,多米尼加藍珀,還有國內的撫順琥珀.
1900/1/1 0:00:00來源:每日經濟新聞 稀里糊涂受邀進群,25年股齡的“資深股民”老張在微信炒股群里被幣圈項目“套了”100萬……群中有“老師”天天講股票、講財經、講分析,縱橫捭闔,點石成金.
1900/1/1 0:00:00來源:e公司官微 作者:康殷彭勃 新冠肺炎疫情蔓延全球,全球資本市場遭遭受重大沖擊。美股指期貨、原油周一開盤大跌,避險需求促使金價大漲.
1900/1/1 0:00:00


