






 BTC/HKD+3.59%
BTC/HKD+3.59% ETH/HKD+4.32%
ETH/HKD+4.32% LTC/HKD+6.33%
LTC/HKD+6.33% DOT/HKD+1.66%
DOT/HKD+1.66% ADA/HKD+5.47%
ADA/HKD+5.47% SOL/HKD+3.07%
SOL/HKD+3.07% XRP/HKD+3.95%
XRP/HKD+3.95% DOGE/US+5.93%
DOGE/US+5.93%“Theonlysimpletruthisthatthereisnothingsimpleinthiscomplexuniverse.Everythingrelates.Everythingconnects”
—JohnnyRich,TheHumanScript
介紹
機器學習的主要應用之一是對隨機過程建模。機器學習中一些隨機過程的例子如下:
泊松過程:用于處理等待時間以及隊列。隨機漫步和布朗運動過程:用于交易算法。馬爾可夫決策過程:常用于計算生物學和強化學習。高斯過程:用于回歸和優化問題(如,超參數調優和自動機器學習)。自回歸和移動平均過程:用于時間序列分析(如,ARIMA模型)。在本文中,我將簡要地向你介紹這些隨機過程。
歷史背景
隨機過程是我們日常生活的一部分。隨機過程之所以如此特殊,是因為隨機過程依賴于模型的初始條件。在上個世紀,許多數學家,如龐加萊,洛倫茲和圖靈都被這個話題所吸引。
如今,這種行為被稱為確定性混沌,它與真正的隨機性有著截然不同的范圍界限。
由于愛德華·諾頓·洛倫茲的貢獻,混沌系統的研究在1963年取得了突破性進展。當時,洛倫茲正在研究如何改進天氣預報。洛倫茲在他的分析中注意到,即使是大氣中的微小擾動也能引起氣候變化。
洛倫茲用來描述這種狀態的一個著名的短語是:
“AbutterflyflappingitswingsinBrazilcanproduceatornadoinTexas”(在巴西,一只蝴蝶扇動翅膀就能在德克薩斯州制造龍卷風)—EdwardNortonLorenz(愛德華·諾頓·洛倫茲)
這就是為什么今天的混沌理論有時被稱為“蝴蝶效應”。
分形學
一個簡單的混沌系統的例子是分形(如圖所示)。分形是在不同尺度上不斷重復的一種模式。由于分形的縮放方式,分形不同于其他類型的幾何圖形。分形是遞歸驅動系統,能夠捕獲混沌行為。在現實生活中,分形的例子有:樹、河、云、貝殼等。
天啟資本TraderT:交易策略在不同時間的市場里要隨機應變:據官方消息,Gate.io直播專訪節目《分析是道》20210319期已結束,本期直播邀請到天啟資本的首席交易員Trader T,和大家分享了高頻交易策略在市場上的應用以及如何成為更好的交易員。Trader T認為,面對不同時期的市場交易策略一定要隨機應變,高頻交易策略收益相對穩定,可以說是糾正市場“錯誤的波動”來獲利,但付出精力與時間都是成正比的,熱門的Token與優秀的交易平臺比如GATE是高頻交易盈利的基礎。成為更好的專業交易員需要大量的經驗積累,并且會伴隨著相對乏味的生活,賺錢一定不能特別著急,重要的是細水長流,保持良好交易心態并找到自己的規律。[2021/3/19 19:02:10]

圖1:MC.Escher,SmallerandSmaller
在藝術領域有很多自相似的圖形。毫無疑問,MC.Escher是最著名的藝術家之一,他的作品靈感來自數學。事實上,在他的畫中反復出現各種不可能的物體,如彭羅斯三角形和莫比烏斯帶。在"SmallerandSmaller"中,他也反復使用了自相似性(圖1)。除了蜥蜴的外環,畫中的內部圖案也是自相似性的。每重復一次,它就包含一個有一半尺度的復制圖案。
確定性和隨機性過程
有兩種主要的隨機過程:確定性和隨機性。
在確定性過程中,如果我們知道一系列事件的初始條件(起始點),我們就可以預測該序列的下一步。相反,在隨機過程中,如果我們知道初始條件,我們不能完全確定接下來的步驟是什么。這是因為這個過程可能會以許多不同的方式演化。
在確定性過程中,所有后續步驟的概率都為1。另一方面,隨機性隨機過程的情況則不然。
TAAL提交新專利申請 專利涉及生成高質量的隨機數:TAAL分布式信息技術公司(TAAL)宣布,其運營子公司已經向英國專利局提交了一份專利申請。TAAL認為,除了生成區塊和保護區塊鏈之外,部署在數據中心(即礦場)的計算能力還可以用于其他用途。據悉,該專利涉及生成大量高質量的隨機數。過去,由于需要隨機的環境輸入,這些隨機數的生成既繁瑣又昂貴。反過來,這些高質量的隨機數有多個用例,可用于復雜的計算應用程序,如可用于科學、醫療跟蹤研究的人工智能(AI)建模場景以及高需求的金融計算機模擬。(美通社)[2020/4/3]
任何完全隨機的東西對我們都沒有任何用處,除非我們能識別出其中的模式。在隨機過程中,每個單獨的事件都是隨機的,盡管可以識別出連接這些事件的隱藏模式。這樣,我們的隨機過程就被揭開了神秘的面紗,我們就能夠對未來的事件做出準確的預測。
為了用統計學的術語來描述隨機過程,我們可以給出以下定義:
觀測值:一次試驗的結果。總體:所有可能的觀測值,可以記為一個試驗。樣本:從獨立試驗中收集的一組結果。例如,拋一枚均勻硬幣是一個隨機過程,但由于大數定律,我們知道,如果進行大量的試驗,我們將得到大約相同數量的正面和反面。
大數定律指出:
“隨著樣本規模的增大,樣本的均值將更接近總體的均值或期望值。因此,當樣本容量趨于無窮時,樣本均值收斂于總體均值。重要的一點是樣本中的觀測必須是相互獨立的。”--JasonBrownlee
隨機過程的例子有股票市場和醫學數據,如血壓和腦電圖分析。
泊松過程
泊松過程用于對一系列離散事件建模,在這些事件中,我們知道不同事件發生的平均時間,但我們不知道這些事件確切在何時發生。
如果一個隨機過程能夠滿足以下條件,則可以認為它屬于泊松過程:
事件彼此獨立(如果一個事件發生,并不會影響另一個事件發生的概率)。兩個事件不能同時發生。事件的平均發生比率是恒定的。讓我們以停電為例。電力供應商可能會宣傳平均每10個月就會斷電一次,但我們不能準確地說出下一次斷電的時間。例如,如果發生了嚴重問題,可能會連續停電2-3天(如,讓公司需要對電源供應做一些調整),以便在接下來的兩天繼續使用。
聲音 | 慢霧預警:攻擊者喊話所有鏈上偽隨機數(PRNG)都可被攻擊:攻擊者 floatingsnow 向自己的子賬號 norealrandom、dolastattack 轉賬并在 memo 中喊話:hi slowmist/peckshield: not only timer-mix random but all in-chain PRNG can be attack, i suggest b1 export new apis (get_current_blockid/get_blockhash_by_id) instead of prefix/num
從賬號名稱和 memo 可知攻擊者對目前 EOS DApp 鏈上隨機數方案了如指掌,攻擊者指出 tapos_block_prefix/tapos_block_num 均不安全,并提議 b1 新增 get_current_blockid / get_blockhash_by_id 接口。[2019/1/16]
因此,對于這種類型的隨機過程,我們可以相當確定事件之間的平均時間,但它們是在隨機的間隔時間內發生的。
由泊松過程,我們可以得到一個泊松分布,它可以用來推導出不同事件發生之間的等待時間的概率,或者一個時間段內可能發生事件的數量。
泊松分布可以使用下面的公式來建模(圖2),其中k表示一個時期內可能發生的事件的預期數量。
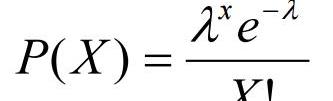
圖2:泊松分布公式
一些可以使用泊松過程模擬的現象的例子是原子的放射性衰變和股票市場分析。
隨機漫步和布朗運動過程
隨機漫步是可以在隨機方向上移動的任意離散步的序列(長度總是相同)(圖3)。隨機漫步可以發生在任何維度空間中(如:1D,2D,nD)。
美國國家標準和技術研究所的研究人員宣布 密碼學中隨機數的方面出現突破:美國國家標準和技術研究所的研究人員最近宣布,在密碼學最重要的一個“隨機數的產生”方面取得了突破。這種實驗性的新技術可能會對網絡安全產生巨大影響。在以電子方式運行現代世界的“1”和“0”的數字面紗后面,隨機數字每天都要在加密過程中進行數千億次的排序,這些過程通過不斷擴大的互聯網為全球提供數據。[2018/4/19]

圖3:高維空間中的隨機漫步
現在我將用一維空間(數軸)向您介紹隨機漫步,這里解釋的這些概念也適用于更高維度。
我們假設我們在一個公園里,我們看到一只狗在尋找食物。它目前在數軸上的位置為0,它向左或向右移動找到食物的概率相等(圖4)。
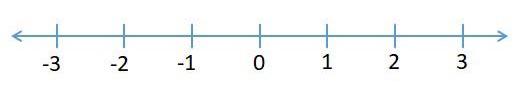
圖4:數軸
現在,如果我們想知道在N步之后狗的位置是多少,我們可以再次利用大數定律。利用這個定律,我們會發現當N趨于無窮時,我們的狗可能會回到它的起點。無論如何,此時這種情況并沒有多大用處。
因此,我們可以嘗試使用均方根(RMS)作為距離度量(首先對所有值求平方,然后計算它們的平均值,最后對結果求平方根)。這樣,所有的負數都變成正數,平均值不再等于零。
在這個例子中,使用RMS我們會發現,如果我們的狗走了100步,它平均會從原點移動10步(√100=10)。
如前面所述,隨機漫步用于描述離散時間過程。相反,布朗運動可以用來描述連續時間的隨機漫步。
隱馬爾科夫模型
丹華資本Doyey Wan:隨機性是挖礦過程中的重要屬性:2月21日消息,今日,Dovey Wan在區塊鏈第一社群“三點鐘無眠區塊鏈”里發表觀點稱:隨機性是挖礦過程中的重要屬性,是保證分布式記賬公平公正的基石。當前的全球算力約為9211434 TH/s,每產生一個符合條件的隨機值大概需要十分鐘的計算,也就是需要嘗試9211434 T * 10 * 60 次哈希運算,每一次嘗試計算得出正確結果的可能性都是隨機分布的。在假設挖礦節點足夠多的情況下,多次連續被同一節點找到正確解的可能性是很低的,從而保證挖礦的公平性。[2018/2/21]
隱馬爾可夫模型都是關于認識序列信號的。它們在數據科學領域有大量應用,例如:
計算生物學。寫作/語音識別。自然語言處理(NLP)。強化學習HMMs是一種概率圖形模型,用于從一組可觀察狀態預測隱藏(未知)狀態序列。
這類模型遵循馬爾可夫過程假設:
“鑒于我們知道現在,所以未來是獨立于過去的"
因此,在處理隱馬爾可夫模型時,我們只需要知道我們的當前狀態,以便預測下一個狀態(我們不需要任何關于前一個狀態的信息)。
要使用HMMs進行預測,我們只需要計算隱藏狀態的聯合概率,然后選擇產生最高概率(最有可能發生)的序列。
為了計算聯合概率,我們需要以下三種信息:
初始狀態:任意一個隱藏狀態下開始序列的初始概率。轉移概率:從一個隱藏狀態轉移到另一個隱藏狀態的概率。發射概率:從隱藏狀態移動到觀測狀態的概率舉個簡單的例子,假設我們正試圖根據一群人的穿著來預測明天的天氣是什么(圖5)。
在這種例子中,不同類型的天氣將成為我們的隱藏狀態。晴天,刮風和下雨)和穿的衣服類型將是我們可以觀察到的狀態(如,t恤,長褲和夾克)。初始狀態是這個序列的起點。轉換概率,表示的是從一種天氣轉換到另一種天氣的可能性。最后,發射概率是根據前一天的天氣,某人穿某件衣服的概率。
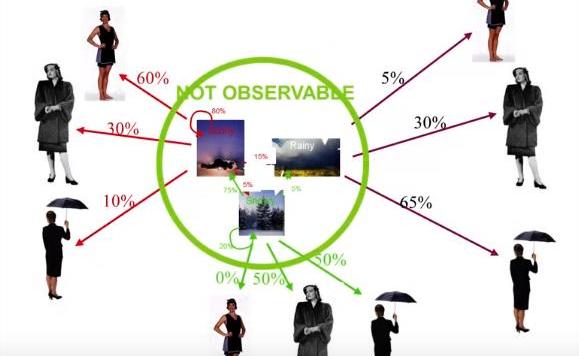
圖5:隱馬爾可夫模型示例
使用隱馬爾可夫模型的一個主要問題是,隨著狀態數的增加,概率和可能狀態的數量呈指數增長。為了解決這個問題,可以使用維特比算法。
如果您對使用HMMs和生物學中的Viterbi算法的實際代碼示例感興趣,可以在我的Github代碼庫中找到它。
從機器學習的角度來看,觀察值組成了我們的訓練數據,隱藏狀態的數量組成了我們要調優的超參數。
機器學習中HMMs最常見的應用之一是agent-based情景,如強化學習(圖6)。
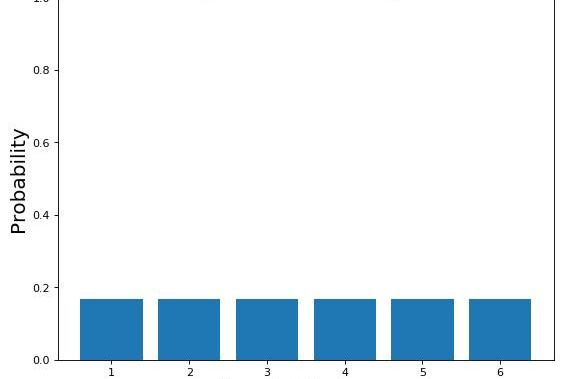
圖7:擲骰子公平的概率分布
無論如何,你玩得越多,你就越可以看到到骰子總是落在相同的面上。此時,您開始考慮骰子可能是不公平的,因此您改變了關于概率分布的最初信念(圖8)。
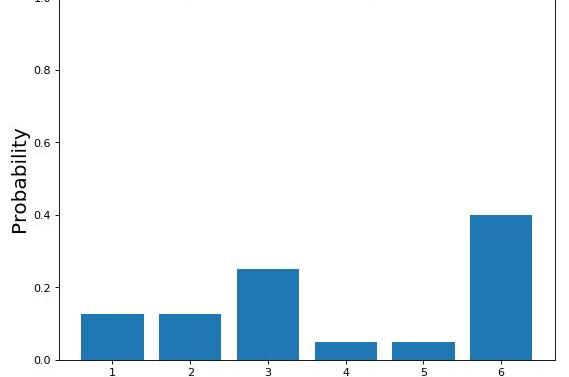
圖8:不公平骰子的概率分布
這個過程被稱為貝葉斯推理。
貝葉斯推理是我們在獲得新證據的基礎上更新自己對世界的認知的過程。
我們從一個先前的信念開始,一旦我們用全新的信息更新它,我們就構建了一個后驗信念。這種推理同樣適用于離散分布和連續分布。
因此,高斯過程允許我們描述概率分布,一旦我們收集到新的訓練數據,我們就可以使用貝葉斯法則(圖9)更新分布。
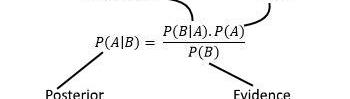
圖9:貝葉斯法則
自回歸移動平均過程
自回歸移動平均(ARMA)過程是一類非常重要的分析時間序列的隨機過程。ARMA模型的特點是它們的自協方差函數只依賴于有限數量的未知參數(對于高斯過程是不可能的)。
縮略詞ARMA可以分為兩個主要部分:
自回歸=模型利用了預先定義的滯后觀測值與當前滯后觀測值之間的聯系。移動平均=模型利用了殘差與觀測值之間的關系。ARMA模型利用兩個主要參數(p,q),分別為:
p=滯后觀測次數。q=移動平均窗口的大小。ARMA過程假設一個時間序列在一個常數均值附近均勻波動。如果我們試圖分析一個不遵循這種模式的時間序列,那么這個序列將需要被差分,直到分割后的序列具有平穩性。
這可以通過使用一個ARIMA模型來實現,如果你有興趣了解更多,我寫了一篇關于使用ARIMA進行股票市場分析的文章。
謝謝閱讀!
參考文獻
MCEscher,“SmallerandSmaller”—1956.訪問:https://www.etsy.com/listing/288848445/m-c-escher-print-escher-art-smaller-and
機器學習中大數定律的簡要介紹。MachineLearningMastery,JasonBrownlee.訪問:https://machinelearningmastery.com/a-gentle-introduction-to-the-law-of-large-numbers-in-machine-learning/
正態分布,二項分布,泊松分布,MakeMeAnalyst.訪問:http://makemeanalyst.com/wp-content/uploads/2017/05/Poisson-Distribution-Formula.png
通用維基百科.Accessedat:https://commons.wikimedia.org/wiki/File:Random_walk_25000.gif
數軸是什么?MathematicsMonste.訪問:https://www.mathematics-monster.com/lessons/number_line.html
機器學習算法:SD(σ)-貝葉斯算法.SagiShaier,Medium.訪問:https://towardsdatascience.com/ml-algorithms-one-sd-%CF%83-bayesian-algorithms-b59785da792a
DeepMind的人工智能正在自學跑酷,結果非常令人驚訝。TheVerge,JamesVincent.訪問:https://www.theverge.com/tldr/2017/7/10/15946542/deepmind-parkour-agent-reinforcement-learning
為數據科學專業人員寫的強大的貝葉斯定理介紹。KHYATIMAHENDRU,AnalyticsVidhya.Accessedat:https://www.analyticsvidhya.com/blog/2019/06/introduction-powerful-bayes-theorem-data-science/
viahttps://towardsdatascience.com/stochastic-processes-analysis-f0a116999e4
今日資源推薦:AI入門、大數據、機器學習免費教程
35本世界頂級原本教程限時開放,這類書單由知名數據科學網站KDnuggets的副主編,同時也是資深的數據科學家、深度學習技術愛好者的MatthewMayo推薦,他在機器學習和數據科學領域具有豐富的科研和從業經驗。
點擊鏈接即可獲取:https://ai.yanxishe.com/page/resourceDetail/417
雷鋒網雷鋒網雷鋒網
《笠翁對韻》第3集 王偉勇教授主講 2017年2月22日 學生:向老師行鞠躬禮,老師好。 老師:同學早,請坐。 學生:謝謝老師。 老師:昨天回去有把一東韻一段、二段、三段都念一遍的請舉手.
1900/1/1 0:00:0011月4日,首屆騰訊醫學ME大會(以下簡稱“ME大會”)在北京舉行,來自全球頂尖的醫學科學家共聚,展現癌癥、艾滋病等醫學領域的最新前沿進展,推動先鋒醫學與大眾健康的連接,啟蒙對真實醫學的認知.
1900/1/1 0:00:00此前我們報道過,全新一代沃爾沃V60將會以整車進口引入的方式于8月6日在國內正式上市。日前,該車已在中國臺灣正式上市,動力上提供T4、T5以及T6插電式混動版本三種動力車型.
1900/1/1 0:00:00區塊鏈和比特幣什么關系?隨著區塊鏈技術話題越來越火熱,也引起了不少人的關注,其實比較早進入大眾視野的是比特幣,你可以理解為比特幣是區塊鏈技術表現,區塊鏈和比特幣都不是具體的物品.
1900/1/1 0:00:00“感覺像刺一樣”《進擊的夢想家》的美女主持人話音未落,只聽得“啪!”的一聲,李國慶把桌子上的水杯直接摔到了地上.
1900/1/1 0:00:00近日,美國科技巨頭谷歌稱已經設計出超越世界上最快的超級計算機計算能力的量子計算機。這臺量子計算機只需200秒即可完成計算任務,而世界上最快的超級計算機需要1萬年才能完成同樣的計算任務.
1900/1/1 0:00:00


