






 BTC/HKD+0.77%
BTC/HKD+0.77% ETH/HKD+1.19%
ETH/HKD+1.19% LTC/HKD+0.75%
LTC/HKD+0.75% DOT/HKD+1.16%
DOT/HKD+1.16% ADA/HKD+2.8%
ADA/HKD+2.8% SOL/HKD+3.82%
SOL/HKD+3.82% XRP/HKD+1.37%
XRP/HKD+1.37% DOGE/US+1.8%
DOGE/US+1.8%撰文:Tanya Malhotra
來源:Marktechpost
編譯:DeFi 之道

圖片來源:由無界版圖AI工具生成
隨著生成性人工智能在過去幾個月的巨大成功,大型語言模型(LLM)正在不斷改進。這些模型正在為一些值得注意的經濟和社會轉型做出貢獻。OpenAI 開發的 ChatGPT 是一個自然語言處理模型,允許用戶生成有意義的文本。不僅如此,它還可以回答問題,總結長段落,編寫代碼和電子郵件等。其他語言模型,如 Pathways 語言模型(PaLM)、Chinchilla 等,在模仿人類方面也有很好的表現。
跨鏈路由協議Multichain推出ETH免費跨鏈活動:1月18日消息,跨鏈路由協議Multichain推出ETH免費跨鏈活動,在其平臺上跨鏈ETH至任意區塊鏈將不收取手續費,僅收取$0.19Gasfee(跨回Ethereum為4.9美元)。
Multichain作為跨鏈基礎設施的建設者,一直致力于推動多鏈生態發展,目前已經連通81條主流公鏈,支持超過3200種資產跨鏈,是web3領域最主要的跨鏈交互協議。[2023/1/18 11:18:09]
大型語言模型使用強化學習(reinforcement learning,RL)來進行微調。強化學習是一種基于獎勵系統的反饋驅動的機器學習方法。代理(agent)通過完成某些任務并觀察這些行動的結果來學習在一個環境中的表現。代理在很好地完成一個任務后會得到積極的反饋,而完成地不好則會有相應的懲罰。像 ChatGPT 這樣的 LLM 表現出的卓越性能都要歸功于強化學習。
Wing將發布OKExChain版本:去中心化跨鏈借貸平臺Wing發推稱,WIP-36經過投票已經正式通過,官方將發布OKExChain版本Wing。[2021/4/29 21:10:22]
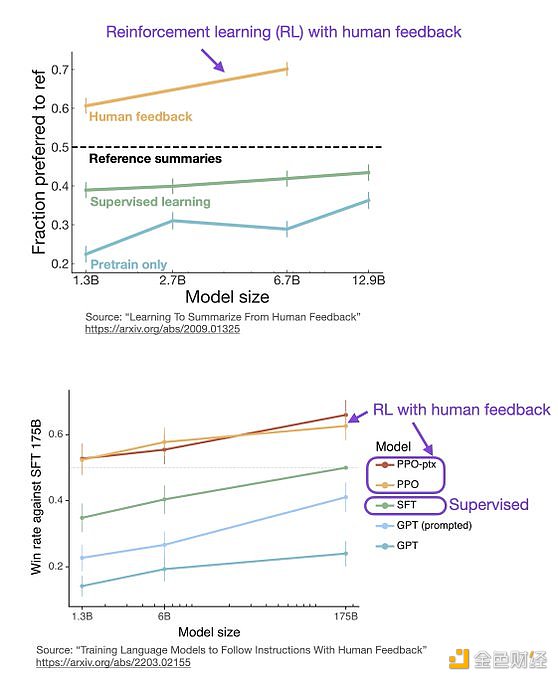
ChatGPT 使用來自人類反饋的強化學習(RLHF),通過最小化偏差對模型進行微調。但為什么不是監督學習(Supervised learning,SL)呢?一個基本的強化學習范式由用于訓練模型的標簽組成。但是為什么這些標簽不能直接用于監督學習方法呢?人工智能和機器學習研究員 Sebastian Raschka 在他的推特上分享了一些原因,即為什么強化學習被用于微調而不是監督學習。
動態 | ChainAnalysis員工在Reddit發帖揭露公司相關信息:據AMBCrypto報道,Chainalysis一名員工(化名為Chainalysis1)在Reddit要求用戶對該公司、其功能或任何與加密貨幣相關的問題。 有用戶提問,Chainalysis這樣的公司是否會因為不同的網絡技術或鏈上隱私的改善而被淘汰。Chainalysis1稱,“是的。毫無疑問。即使只是隱私幣,現在也是任何人都無法處理的,但是加入匿名化技術,適于法庭的追蹤實用程序就完成了。他們可能仍有利基目標,但規模將會很小。” 用戶問Chainalysis最討厭的工具是什么。Chainalysis1稱目前Wasabi是“頭號敵人”。該錢包顯然不是用戶喜歡的,因為沒有辦法取消其匿名化。Wasabi的一個關鍵因素是其錢包不能被政府拿走。 有用戶詢問比特幣社區可通過哪些方式改善隱私,進而發展整個生態系統。Chainalysis1稱,“我會說避免移動錢包,看看Wasabi/CoinJoin和類似的努力,隨時運行虛擬專用網/Tor。請記住,你在透明網絡上查看的所有信息都被某人記錄下來。有人可能從事銷售隱私的行業。即使看起來像是一項簡單的服務,看看交易是否已經發布到區塊鏈中。”[2019/6/28]
聲音 | NakaChain創始人林嚇洪:2019年將是穩定幣的元年:近日,針對美國最大的金融服務機構之一摩根大通(J.P.Morgan)在其自有的企業級分布式賬本平臺Quorum 上推出穩定幣摩根幣(JPM Coin)這一動態,NakaChain創始人林嚇洪在接受金色財經采訪時表示,反觀2014-2015年間的熊市,IBM、微軟等大型機構都在布局區塊鏈,但是這種新聞動態對幣價或者對整個市場來說,短期內不會有太大影響,原因有兩點:1)它是區塊鏈基礎設施的建設,不會直接跟某個具體項目掛鉤;2)對整個區塊鏈行業沒有產生實在的用戶需求。
林嚇洪直言,在他看來,摩根大通發布JP Coin是一個很普通的行為,對其火爆行業媒體有些意外。未來,大到企業,小到商家、微信群甚至個人等所有實體都會擁有自己的數字資產,通俗地說就是“人人都能發幣”。但這個“幣”不是ICO,不再有投資屬性,而是有真正的需求,有內在價值錨定的數字貨幣。他解釋說,幣或者Token的定義和用處可以更廣泛,而且必須更廣。這種更廣泛的定義和應用會促使更多的人在區塊鏈行業做更多創新。林嚇洪還表示,2019年將是穩定幣的元年。[2019/2/21]
不使用監督學習的第一個原因是,它只預測等級,不會產生連貫的反應;該模型只是學習給與訓練集相似的反應打上高分,即使它們是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量,而不僅僅是排名分數。
Sebastian Raschka 分享了使用監督學習將任務重新表述為一個受限的優化問題的想法。損失函數結合了輸出文本損失和獎勵分數項。這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題-答案對時才能成功。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話也是必要的,而監督學習無法提供這種獎勵。
不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的。
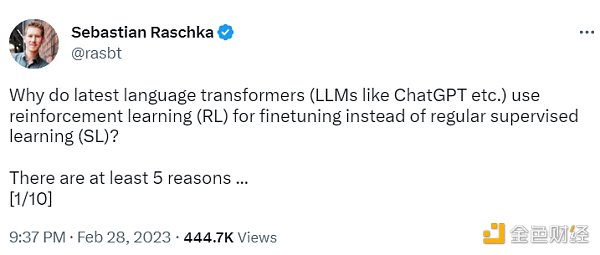
監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好。2022 年的一篇論文《從人類反饋中學習總結》顯示,RLHF 比 SL 表現得更好。原因是 RLHF 考慮了連貫性對話的累積獎勵,而 SL 由于其文本段落級的損失函數而未能很好做到這一點。
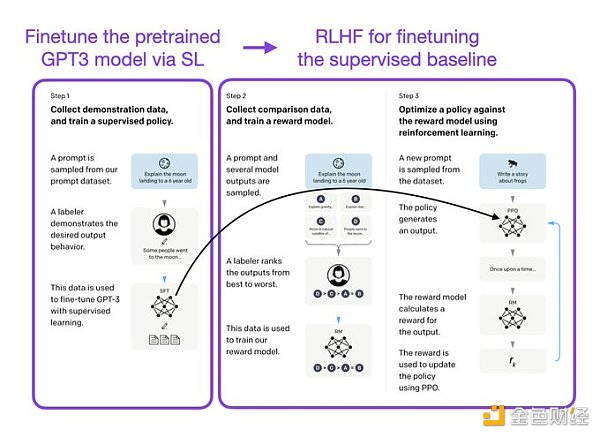
像 InstructGPT 和 ChatGPT 這樣的 LLMs 同時使用監督學習和強化學習。這兩者的結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,然后使用 RL 進一步更新。SL 階段允許模型學習任務的基本結構和內容,而 RLHF 階段則完善模型的反應以提高準確性。
DeFi之道
個人專欄
閱讀更多
金色財經 善歐巴
金色早8點
Odaily星球日報
歐科云鏈
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新聞
撰寫:Kaduna 編譯:深潮 TechFlow最近一段時間,通過 Ordinals 和Stacks,比特幣一直在經歷文化和技術的轉變,而在 Stacks 上有一個項目有望在未來脫穎而出.
1900/1/1 0:00:00原文作者:Natalie Mullins原文編譯:深潮 TechFlow到目前為止,MEV 的話題幾乎只集中在以太坊上。但是,本文將探討 Solana 和 Cosmos 生態系統中的 MEV.
1900/1/1 0:00:00“一種基于文本指令創建繪圖的算法” - MidJourney你現在看到的是文字——文字作為一種媒介,讓我向你傳達一連串的想法.
1900/1/1 0:00:00來源:香港金融管理局官網注:本文發表于2月16日。金管局今日(2月16日)協助政府發行代幣化綠色債券。這是第一只循香港法律制度發行的代幣化債券,亦是全球首只由政府發行的代幣化綠色債券.
1900/1/1 0:00:00原文:NIVESH RUSTGI 編譯:0xAR 自從 2 月 14 日代幣上架和空投就位之后,Blur 市場上 NFT 交易量和賣方流動性急劇上升.
1900/1/1 0:00:002023年世界經濟論壇年會于2023年1月16日至20日在達沃斯舉行,這是世界經濟論壇時隔三年回歸線下。與1971年達沃斯論壇第一次舉辦時相比,如今達沃斯的雪量已經減少了40%以上.
1900/1/1 0:00:00


