






 BTC/HKD+0.04%
BTC/HKD+0.04% ETH/HKD+0.09%
ETH/HKD+0.09% LTC/HKD+0.51%
LTC/HKD+0.51% DOT/HKD+1.79%
DOT/HKD+1.79% ADA/HKD-1.16%
ADA/HKD-1.16% SOL/HKD+0.27%
SOL/HKD+0.27% XRP/HKD+0.39%
XRP/HKD+0.39% DOGE/US-0.21%
DOGE/US-0.21%來源:AI之勢
今年美國科羅拉多州博覽會的藝術比賽上,游戲設計師 Jason M. Allen 的作品《太空歌劇院》在數字藝術板塊得到一等獎。獎項本身含金量不大,卻一石激起千層浪,因為這幅畫不是由人動手繪制,而是來自生成式 AI (Generative AI) 產品 Midjourney。
當時藝術正統和機器褻瀆引發了爭議,其實早在攝影技術興起時就有過類似的爭議,并不妨礙攝影技術革新并,成為了現代藝術的有機組成部分。
因此本文不對此問題做太多探討,而是旨在對生成式 AI 發展與突破的歷史進行復盤,并梳理生成式 AI 會在自然語言、代碼、圖片、視頻、3D 模型等領域帶來什么樣的下游應用。
回顧歷史,人類藝術的發展速度是對數式的,而技術的進步速度是指數式的。生成式 AI 學習了人類藝術對數進化史上的海量畫作,實現了創作質量上的指數式進步,并在生產效率上實現了”彎道超車“。模型生成的作品便是今天熱議的AIGC (AI Generated Content)。
而本文聚焦的公司 OpenAI ,在這場生成式 AI 的突破中起到了關鍵性的作用,通過堆疊海量算力的大模型(Foundation Model)使 AIGC 進化。
在 2022 年上半年,OpenAI 旗下三個大模型 GPT-3、GitHub Copilot 和 DALL·E2 的注冊人數均突破了 100 萬人,其中 GPT-3 花了 2 年,GitHub Copilot 花了半年,而 DALL·E2 只用了2個半月達到了這一里程碑,足見這一領域熱度的提升。
研究型企業引領的大模型發展,也給了下游應用領域很大的想象空間,語言生成領域已經在文案生成、新聞撰寫、代碼生成等領域誕生了多家百萬級用戶、千萬級美金收入的公司。
而最出圈的圖片生成領域兩大產品 MidJourney 和 Stable Diffusion 都已經有相當大的用戶群體,微軟也已經布局在設計軟件中為視覺設計師提供 AIGC 內容,作為設計靈感和素材的來源。同時 3D 和視頻生成領域的大模型也在飛速突破的過程中,未來很可能會在游戲原畫、影視特效、文物修復等領域發揮作用。
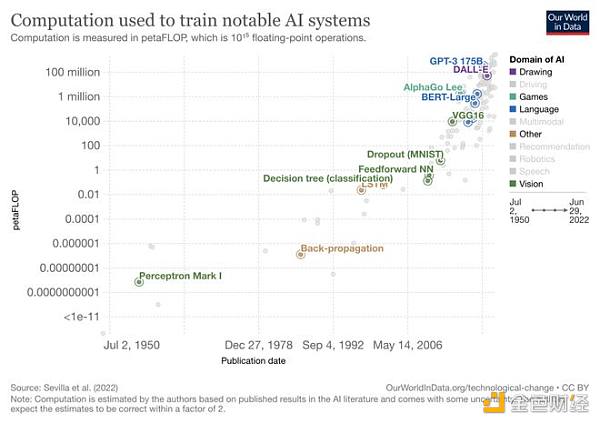
從神經網絡的角度看,當前的大模型 GPT-3 有 1750 億參數,人類大腦有約 100 萬億神經元,約 100 個神經元會組成一個皮質柱,類似于一個小的黑盒神經網絡模塊,數量級上的差異決定了算力進步可以發展的空間還很大。與此同時,今天訓練 1750 億參數的 GPT-3 的成本大概在 450 萬美元左右,根據成本每年降低約 60% 的水平,供大模型提升計算復雜度的空間還很多。
OpenAI CEO、YC 前主席 Sam Altman 的圖景中,AI 大模型發展的最終目標是 AGI(通用人工智能,Artificial General Intelligence),當這一目標實現的時候,人類經濟社會將實現”萬物的摩爾定律“,即萬物的智能成本無限降低,人類的生產力與創造力得到解放。
AI 模型大致可以分為兩類:決策式 AI 與生成式 AI。
根據機器學習教科書,決策式模型 (Discriminant Model)學習數據中的條件概率分布;生成式模型 (Generative Model)學習數據中的聯合概率分布,兩者的區別在于擅長解決問題的方式不同:
決策式 AI 擅長的是基于歷史預估當下,有兩大類主要的模型應用,一類是輔助決策,常用在推薦系統和風控系統中;第二類是決策智能體,常用于自動駕駛和機器人領域。
生成式 AI 擅長的是歸納后演繹創造,基于歷史進行縫合式創作、模仿式創新——成為創作者飛船的大副。所謂 AIGC(AI Generated Content),便是使用生成式AI主導/輔助創作的藝術作品。
不過在10年代的機器學習教科書中,早已就有了這兩類AI。為何 AIGC 在20年代初有了顯著突破呢?答案是大模型的突破。
時間倒回到 19 年 3 月,強化學習之父 Richard Sutton 發布了名為 The Bitter Lesson(苦澀的教訓)的博客,其中提到:”短期內要使AI能力有所進步,研究者應尋求在模型中利用人類先驗知識;但之于AI的發展,唯一的關鍵點是對算力資源的充分利用。“
黑客利用OpenSea平臺漏洞竊取用戶價值百萬美元的NFT:1月25日消息,據區塊鏈分析公司Elliptic稱,NFT市場 OpenSea 存在一個漏洞,使得黑客能夠以遠低于市場價值的價格從所有者手中搶走罕見的NFT,并將其轉售以賺取豐厚利潤。截至周一,至少有三名攻擊者在過去12小時內以遠低于其市場價值的價格購買了至少8個 NFT,其中包括 Bored Ape Yacht Club、Mutant Ape Yacht Club、Cool Cats 和 Cyberkongz NFT。其中一個化名為“jpegdegenlove”的攻擊者以13.3萬美元的價格購買了7個NFT,然后迅速以93.4萬美元的價格將其出售。硬件錢包開發商 Ledger 的首席技術官 Charles Guillemet 周一在 Twitter 上表示,“現在很難安全地使用這個平臺,我們唯一能做的就是降低風險。
金色財經此前報道,OpenSea前端疑似出現掛單Bug,有人獲利超200ETH。(Blockworks)[2022/1/25 9:11:09]
Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation.
該文章在當時被不少 AI 研究者視為對自己工作的否定,極力辯護。但如果拉長時間線回看,會發現這位泰斗所言不虛:
機器學習模型可以從參數量級上分為兩類:統計學習模型,如 SVM(支持向量機)、決策樹等數學理論完備,算力運用克制的模型;和深度學習模型,以多層神經網絡的深度堆疊為結構,來達到高維度暴力逼近似然解的效果,理論上不優雅但能高效的運用算力進行并行計算。
神經網絡模型在上世紀 90 年代出現,但在 2010 年前,統計學習模型仍是主流;后來得益于 GPU 算力的高速進步,基于神經網絡的深度學習模型逐漸成為主流。
深度學習充分利用了 GPU 擅長并行計算的能力,基于龐大的數據集、復雜的參數結構一次次實現出驚人的效果,刷新預期。大模型便是深度學習模型參數量達到一定量級,只有大型科技公司才能部署的深度學習模型。
2019年,OpenAI 從非營利組織變為營利性公司,接受微軟 10 億美金注資。這一合作奠定了他們有更多算力資源,并能依仗微軟的云基礎建設隨時將大模型(Foundation Model)發布為商用 api。
與此同時,還有第三件事值得關注,大模型 AI 的研究方向出現了轉變,從智能決策式 AI 轉變為內容生成式 AI:原本主要大模型集中于游戲的智能決策體,如 DeepMind 開發的打敗圍棋冠軍的 AlphaGo、OpenAI 開發的打敗 Dota 職業選手的 OpenAI Five。
Transformer 模型(后文將詳細介紹)的發布讓 OpenAI 嗅到了更適合他們的機會——預訓練語言模型。在那之后,他們開始在 AIGC 的方向上開枝散葉:沿著 2018 年時低調發布的 GPT 模型軌跡發布了一系列模型族,一次次刷新文本生成大模型的效果,印證 Sutton 提出的宗旨:充分運用海量算力讓模型自由的進行探索和學習。
2019年2月:GPT-2 初版發布,1.2 億參數量
2019年3月:OpenAI LP 成立
2019年7月:微軟注資 10 億美金
2019年11月:GPT-2 最終版發布,15 億參數量,宣布暫時不開放使用為避免假信息偽造
2020年6月:GPT-3 發布,1750 億參數量,后續開放 OpenAI API 作為商用
2021年1月:DALL·E 與 CLIP 發布
2021年10月:OpenAI Codex 發布,為 GPT-3 為 coding 場景的特化模型、Github Copilot 的上游模型
拳王泰森在OpenSea上發布NFT收藏品并開啟拍賣:8月20日消息,拳王邁克·泰森(Mike Tyson)在NFT平臺OpenSea上發布了一系列NFT收藏品。55歲的泰森與數字藝術家Cory Van Lew合作,推出了“邁克·泰森NFT收藏品”(Mike Tyson NFT Collection),其中包括11件供拍賣的唯一NFT,以及6件開放式NFT,每件NFT數量在50至250不等。這些藏品于今天早些時候發布,NFT用霓虹色描繪了泰森職業生涯中的標志性時刻,如擊倒對手、贏得冠軍和“咬耳朵”事件。
截至發稿時還有三件唯一NFT,其中最高競價為5 ETH,價值約16000美元。但由于拍賣要到8月24日才結束,價格可能會快速攀升。泰森還在推特上表示,“即購”版NFT在推出一小時內就已售罄。據悉,此次為泰森聯合1 Of One工作室發行的首個官方系列NFT。(Cointelegraph)[2021/8/20 22:26:24]
2022年4月:DALL·E2 發布
1、GPT-3,AI文本生成巔峰之作
深度學習興起于計算機視覺領域的應用,而大模型的發展開始于 NLP 領域。在數據、算力充分發展的過程中,Transformer 模型以 attention 機制高度并行化的結構充分利用算力,成為 NLP 領域預訓練模型的標桿。
著名的獨角獸 Hugging Face 也是從對該模型的復現和開源起家。除了 attention 機制的高效之外,它還有兩個重要特點:遷移學習(transfer learning)和自監督學習(self-supervised learning)。
顧名思義,遷移學習指在一個極龐大的數據集上充分學習歷史上的各類文本,把經驗遷移到其他文本上。
算法工程師會將第一步訓練完成的模型存儲下來,稱為預訓練模型。需要執行具體任務時,基于預訓練版本,進行定制化微調(fine-tune)、或展示少許范例(few-shot/zero-shot)。
而自監督學習,得從機器學習中的監督學習講起。前面提到若需要學習一匹馬是否在奔跑,需要有一個完整標注好的大數據集。
自監督學習不需要,當 AI 拿到一個語料庫,可以通過遮住一句話中的某個單詞、遮住某句話的下一句話的方式,來模擬一個標注數據集,幫模型理解每個詞的上下文語境,找到長文本之間的關聯。該方案大幅提高了對數據集的使用效率。
谷歌發布的 BERT 是 Transformer 時代的先驅,OpenAI 發布的 GPT-2 以相似的結構、更勝一籌的算力后來居上。直到2020年6月,OpenAI 發布了 GPT-3,成為該模型族,甚至整個文本生成領域的標桿。
GPT-3 的成功在于量變產生質變:參數比 GPT-2 多了兩個數量級(1750億vs 15億個參數),它用的最大數據集在處理前容量達到 45TB。
如此巨大的模型量級,效果也是史無前例的。給 GPT-3 輸入新聞標題”聯合衛理公會同意這一歷史性分裂“和副標題”反對同性戀婚姻的人將創建自己的教派“,生成了一則以假亂真的新聞,評估人員判斷出其為AI生成的準確率僅為 12%。以下是這則新聞的節選:
據《華盛頓郵報》報道,經過兩天的激烈辯論,聯合衛理公會同意了一次歷史性的分裂:要么創立新教派,要么”保持神學和社會意義上的保守“。大部分參加五月教會年度會議的代表投票贊成進一步禁止 LGBTQ 神職人員的任命,并制定新的規則”規范“主持同性婚禮的神職人員。但是反對這些措施的人有一個新計劃:于2020 年組成一個新教派”基督教衛理公會“。

要達到上述效果,成本不容小覷:從公開數據看,訓練一個 BERT 模型租用云算力要花約 1.2 萬美元,訓練 GPT-2 每小時要花費 256 美元,但 OpenAI 并未公布總計時間成本。考慮到 GPT-3 需要的算力是 BERT 的 2000 多倍,預估發布當時的訓練成本肯定是千萬美元級別,以至于研究者在論文第九頁說:我們發現了一個 bug,但沒錢再去重新訓練模型,就先這么算了吧。

OpenEthereum官方:API暫停服務事件提醒節點保持最新狀態:以太坊核心開發者Martin Swende晚間轉發Nikita Zhavoronkov關于Infura以太坊API服務中斷的推文并稱,較舊的geth版本包含共識缺陷,這些缺陷今天在主網上遭到了攻擊。引入的更改實際上是在解決這些問題。這是提醒您使節點保持最新狀態。隨后,OpenEthereum官方轉發并表示,這是一個提醒您將節點更新到openeanthem 3.1的提示。[2020/11/11 12:21:12]
2、背后DALL·E 2,從文本到圖片
GPT-3殺青后,OpenAI 把大模型的思路遷移到了圖片多模態(multimodal)生成領域,從文本到圖片主要有兩步:多模態匹配:將 AI 對文本的理解遷移至對圖片的理解;圖片生成:生成出最符合要求的高質量圖片。
對于多模態學習模塊,OpenAI 在 2021 年推出了 CLIP 模型,該模型以人類的方式瀏覽圖像并總結為文本內容,也可以轉置為瀏覽文本并總結為圖像內容(DALL·E 2中的使用方式)。
CLIP (Contrastive Language-Image Pre-Training) 最初的核心思想比較簡單:在一個圖像-文本對數據集上訓練一個比對模型,對來自同一樣本對的圖像和文本產生高相似性得分,而對不匹配的文本和圖像產生低相似性分(用當前圖像和訓練集中的其他對的文本構成不匹配的樣本對)。
對于內容生成模塊,前面探討了文本領域:10 年代末 NLP 領域生成模型的發展,是 GPT-3 暴力出奇跡的溫床。而計算機視覺 CV 領域 10 年代最重要的生成模型是 2014 年發布的生成對抗網絡(GAN),紅極一時的 DeepFake 便是基于這個模型。GAN的全稱是 Generative Adversarial Networks——生成對抗網絡,顯然”對抗“是其核心精神。
注:受博弈論啟發,GAN 在訓練一個子模型A的同時,訓練另一個子模型B來判斷它的同僚A生成的是真實圖像還是偽造圖像,兩者在一個極小極大的博弈中不斷變強。
當A生成足以”騙“過B的圖像時,模型認為它比較好地擬合出了真實圖像的數據分布,進而用于生成逼真的圖像。當然,GAN方法也存在一個問題,博弈均衡點的不穩定性加上深度學習的黑盒特性使其生成。
不過 OpenAI 大模型生成圖片使用的已不是 GAN 了,而是擴散模型。2021年,生成擴散模型(Diffusion Model)在學界開始受到關注,成為圖片生成領域新貴。
它在發表之初其實并沒有收到太多的關注,主要有兩點原因:
其一靈感來自于熱力學領域,理解成本稍高;
其二計算成本更高,對于大多高校學術實驗室的顯卡配置而言,訓練時間比 GAN 更長更難接受。
該模型借鑒了熱力學中擴散過程的條件概率傳遞方式,通過主動增加圖片中的噪音破壞訓練數據,然后模型反復訓練找出如何逆轉這種噪音過程恢復原始圖像,訓練完成后。擴散模型就可以應用去噪方法從隨機輸入中合成新穎的”干凈“數據。該方法的生成效果和圖片分辨率上都有顯著提升。

不過,算力正是大模型研發公司的強項,很快擴散模型就在大公司的調試下成為生成模型新標桿,當前最先進的兩個文本生成圖像模型——OpenAI 的 DALL·E 2 和 Google 的 Imagen,都基于擴散模型。DALL·E 2 生成的圖像分辨率達到了 1024 × 1024 像素。例如下圖”生成一幅莫奈風格的日出時坐在田野里的狐貍的圖像“:

除了圖像生成質量高,DALL·E 2 最引以為傲的是 inpainting 功能:基于文本引導進行圖像編輯,在考慮陰影、反射和紋理的同時添加和刪除元素,其隨機性很適合為畫師基于現有畫作提供創作的靈感。比如下圖中加入一只符合該油畫風格的柯基:
OpenSky業務開發經理:歐洲公共部門部署區塊鏈技術的需求日益增長:在歐洲,無論是在國家層面還是在歐盟層面都在考慮通過區塊鏈實現電子政務,而且由于新冠疫情,在線提供公共服務非常重要。
IT咨詢公司OpenSky業務開發經理Susanne McCabe稱,公共支出和改革部的改革部門正在發布有關政府潛在用途和挑戰的指南。區塊鏈越來越多地出現在對話中。然而在政府中,技術必須證明自己。國際上的例子比比皆是,比如愛沙尼亞、瑞典等。OpenSky已申請EU Horizon 2020研究基金,該項目初步利用區塊鏈作為數字驅動因素,與愛爾蘭、德國和西班牙主要合作伙伴保持部分所有權模式的合規性。“去年我們開始這一旅程;雖然該領域有一些非常成熟的關鍵組織為金融服務提供區塊鏈,但我們沒有看到政府方面的專家,這就是我們的切入點。因此,今年我們采取關鍵舉措增強能力,將在2020年底推出Blockchain 4 Government實踐。”她表示愛爾蘭在采用區塊鏈方面處于有利地位。
今年OpenSky成立區塊鏈研究部門。該公司正與一些政府客戶開發概念驗證,研究該技術如何適用于其各自任務,并與戰略合作伙伴微軟和PA Consulting合作。(Businesspost)[2020/5/31]

DALL·E 2 發布才五個月,尚沒有 OpenAI 的商業化api開放,但有 Stable Diffusion、MidJourney 等下游公司進行了復現乃至商業化,將在后文應用部分介紹。
3、OpenAI的使命——開拓通往 AGI 之路
AIGC 大模型取得突破,OpenAI 只開放了api和模型思路供大家借鑒和使用,沒去做下游使用場景的商業產品,是為什么呢?因為 OpenAI 的目標從來不是商業產品,而是通用人工智能 AGI。
OpenAI 的創始人 Sam Altman 是 YC 前總裁,投出過 Airbnb、Stripe、Reddit 等明星獨角獸(另一位創始人 Elon Musk 在 18 年因為特斯拉與 OpenAI ”利益相關“離開)。
他在 21 年發布過一篇著名的博客《萬物的摩爾定律》,其中提到 OpenAI,乃至整個 AI 行業的使命是通過實現 AGI 來降低所有人經濟生活中的智能成本。這里所謂 AGI,指的是能完成平均水準人類各類任務的智能體。
因此,OpenAI 始終保持著學術型企業的姿態處于行業上游,成為學界與業界的橋梁。當學界涌現出最新的 state-of-art 模型,他們能抓住機會通過海量算力和數據集的堆疊擴大模型的規模,達到模型意義上的規模經濟。
在此之后克制地開放商業化 api,一方面是為了打平能源成本,更主要是通過數據飛輪效應帶來的模型進化收益:積累更富裕的數據優化迭代下一代大模型,在通往 AGI 的路上走得更堅實。
定位相似的另一家公司是 Deepmind——2010年成立,2014 年被谷歌收購。同樣背靠科技巨頭,也同樣從強化學習智能決策領域起家,麾下的 AlphaGo 名聲在外,Elon Musk 和 Sam Altman 剛開始組局創辦 OpenAI,首要的研究領域就是步 AlphaGo 后塵的游戲決策 AI。
不過 19 年后,兩者的研究重心出現了分叉。DeepMind 轉向使用 AI 解決基礎科學如生物、數學等問題:AlphaFold 在預測蛋白質結構上取得了突破性的進展,另一個 AI 模型 AlphaTensor 自己探索出了一個 50 年懸而未決的數學問題:找到兩個矩陣相乘的最快方法,兩個研究都登上了 Nature 雜志的封面。而 OpenAI 則轉向了日常應用的內容生成 AIGC 領域。
AIGC大模型是通往 AGI 路上極為重要、也有些出乎意料的一站。其重要性體現在 AI 對人類傳達信息的載體有了更好的學習,在此基礎上各個媒介之間的互通成為可能。
例如從自然語言生成編程語言,可以產生新的人機交互方式;從自然語言生成圖片和視頻,可以革新內容行業的生產范式。意外性則是,最先可能被替代的不是藍領,而是創作者,DeepMind 甚至在協助科學家一起探索科研的邊界。
openledger網站EOS和ETH暫時無法訪問:openledger今日發布公告稱,由于網站維修,EOS和ETH暫時無法訪問。[2018/4/20]
OpenAI 的模式也給了下游創業者更多空間。可以類比當年預訓練語言模型發展初期,Hugging Face把握機會成為大模型下游的模型開源平臺,補足了模型規模膨脹下機器學習民主化的市場空間。
而對 AIGC 模型,未來會有一類基于大模型的創業公司,把預訓練完成的 AIGC 模型針對每個子領域進行調優。不只需要模型參數優化,更要基于行業落地場景、產品交互方式、后續服務等,幫助某個行業真正用上大模型。
正如 AI 的 bitter lesson 一樣矛盾,投資者需要短期投資回報率、研究者需要短期投稿成功率,盡管OpenAI 走在通往 AGI 正確的路上,這條路道阻且長,短期很難看到極大的突破。而 Sam Altman 展望的大模型應用層公司很有可能有更高的高投資回報,讓我們來介紹下主要的分類與創業者。
對應 OpenAI 大模型發布的順序,模型應用層相對最成熟的是文本生成領域,其次是圖片生成領域,其他領域由于還未出現統治級的大模型相對落后。
文本領域天然應用場景豐富,且 GPT-3 開放 api 很久,細分賽道很多。大致可以根據生成內容不同分為兩類:機器編程語言生成、人類自然語言生成。前者主要有代碼和軟件行為的生成等,后者主要有新聞撰寫、文案創作、聊天機器人等。
而圖片領域當前還專注于圖片自身內容的生成,預期隨著未來3D、視頻相關內容生成能力的增強,會有更多結合不同業務場景如游戲、影視這樣細分領域的創業公司。
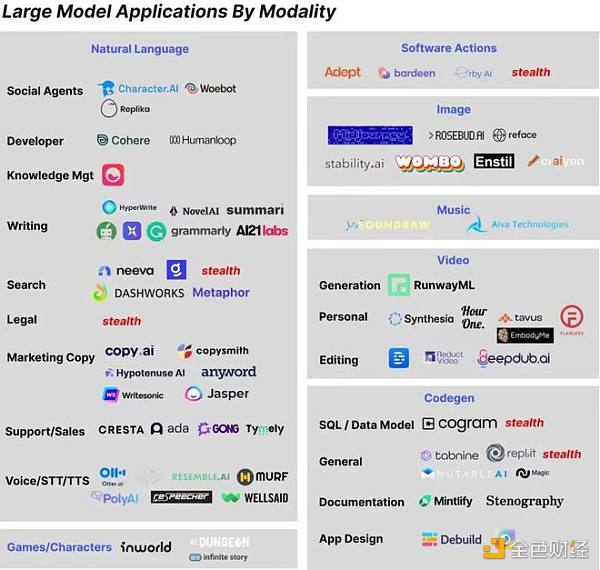
以下是海外各子領域創業公司的梳理,接下來將針對幾個領域的重要公司進行介紹。
1、編程語言
文本領域最成熟的應用暫時不在人類自然語言,而是在代碼等機器語言的生成領域。因為機器語言相對更結構化,易學習;比如鮮有長文本的上下文關系、基于語境的不同含義等情況。
(1)代碼生成:Github Copilot
代表公司是微軟出品的 Github Copilot,編程中的副駕駛。該產品基于 OpenAI 專門用 GPT-3 為編程場景定制的AI模型 Codex。使用者文字輸入代碼邏輯,它能快速理解,根據海量開源代碼生成造好的輪子供開發者使用。提高一家科技公司 10% 的 coding 效率能帶來很大收益,微軟內部已進行推廣使用。
相比低代碼工具,Copilot 的目標群體是代碼工作者。未來的低代碼可能是兩者結合:低代碼 UI 界面實現代碼框架搭建,代碼子模塊通過 Copilot 自動生成。
正如 Copilot 的 slogan:Don’t fly solo,沒有 Copilot 的幫助 coder 的工作會變得繁冗,沒有 coder 的指引 Copilot 生成的內容可能會出現紕漏。也有用戶報告了一些侵犯代碼版權、或代碼泄露的案例,當前技術進步快于版權法規產生了一定的空白。
(2)軟件行為生成:Adept.ai
Adept.ai 是一家明星創業公司。創始團隊中有兩人是Transformer 模型論文作者,CEO 是谷歌大腦中大模型的技術負責人,已經獲得 Greylock 等公司 6500 萬美元的 A 輪融資。

他們的主要產品是大模型 ACT-1,讓算法理解人類語言并使機器自動執行任務。目前產品形態是個 chrome 插件,用戶輸入一句話,能實現單擊、輸入、滾動屏幕行文。在展示 demo中,一位客服讓瀏覽器中自動記錄下與某位顧客的電話,正在考慮買 100 個產品。這個任務需要點擊 10 次以上,但通過 ACT-1 一句話就能完成。
軟件行為生成顛覆的是當下的人機交互形式,使用文字或語音的自然語言形式來代替當下人與機器的圖形交互模式(GUI)。大模型成熟后,人們使用搜索引擎、生產力工具的方式都將變得截然不同。
2、自然語言
自然語言下還有多個應用型文本生成領域值得關注:新聞撰寫、文案創作、對話機器人等。
(1)新聞撰寫
最著名的是 Automated Inights。他們的結構化數據新聞撰寫工具叫做 wordsmith,通過輸入相應數據和優先級排序,能產出一篇基于數據的新聞報道。該工具已在為美聯社每季度自動化產出 300 余篇財報相關報道,在雅虎體育新聞中也已經嶄露頭角。據分析師評價,由 AI 完成的新聞初稿已接近人類記者在 30 分鐘內完成的報道水準。
Narrative Science是另一家新聞撰寫生成公司,其創始人甚至曾預測,到 2030 年,90%以上的新聞將由機器人完成。
(2)文案創作
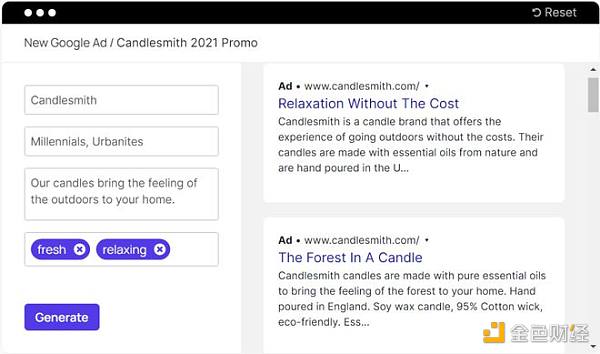
該領域競爭較為激烈,有copy.ai、Jasper、copysmith 等公司。他們基于 GPT-3 的能力加入了文案領域的人工模板與結構,為商家和個人創作者提供了快速為自己的商品、內容進行宣傳的能力。以copysmith 為例:
(3)對話機器人
前面提到的 Adept.ai 由Transformer 模型的一作和三作聯合創立;而二作也創業了,他創辦的 Character.ai 是當前對話機器人中使用效果最逼真的。
該對話機器人可以自定義或使用模板來定義角色的家庭、職業、年齡等,在此基礎上保持一貫的設定和符合設定的對話風格。經常能體現出一定的共情對話能力帶給人驚喜,并且支持多語言互通。
比如他們有已訓練好的馬斯克等名人和一些動漫角色,與他們對話會有很棒的代入感。
而商業化的對話機器人,在客服、銷售等行業有巨大的市場空間,但如今還為成熟。
主要出現的問題有二:
其一,客服、銷售行業遇到的客戶往往情緒狀態不穩定,AI 難以對情緒進行適應并調整對話內容;
其二,AI 的多輪對話能力較弱,無法保證持續有效的跟進問題。
(4)創作性文本
AI 對于長文本創作有一定困難,難以保持1000字以上的文本創作后仍能進行上下文的聯系。
但基于短文本創作仍有一些有趣的應用,例如基于GPT-3的 AI Dungeon,可以引導 AI 創造一個虛擬游戲世界觀。該領域進一步的成長需要期待未來 3-5 年,有成熟的能產出千字內容的 AI 出現。
3、多模態圖片
DALL·E2 是極具突破性的 AIGC 大模型,但距離豐富生產力和創造力的成熟產品還有差距。因此有研究者順著 DALL·E 和 CLIP 的思路開發了開源版本的擴散模型,就像當年的 Hugging Face 那樣,并將其根據創作者社區的反饋轉變為更成熟易用的商業產品。接下來就介紹幾個主要出圈的模型:
(1)Disco Diffusion
最早出圈的 AI 繪圖工具是開源模型Disco Diffusion。發布時間比 DALL·E 2 稍晚,同樣也是 CLIP + Diffusion Model 的結構,生成效果讓許多插畫師擔心起了失業。
盡管很多插畫師和 AI 工具愛好者的推薦都認可了該工具的易用性和生成效果的出眾,但其生成時間略長有待優化,可以認為是大家對圖片生成大模型的初體驗。
(2)MidJourney
該模型發布后不久,Disco Diffusion 的開發者 Somnai 加入了 MidJourney,和團隊一起打造了一款產品化的 Disco Diffusion。
Midjourney 的創始人 David Holz 并不是以CV(計算機視覺)研究為主,更關注人機交互。產品公測和主要交流平臺都基于Discord,使用 Discord Bot 進行交互,打造了相當良好的社區討論環境。
使用中印象深刻的有幾個重要功能:MidJourney 畫廊中可以看到每時每刻創作者們用 MJ 創作出的作品,用戶可以對作品進行打分,每周排名靠前的作品將得到額外的 fast GPU 時間獎勵。
同時,MJ官方還為用戶貼心的提供了引導語 prompt 集合和 AI 擅長的風格指南,指導用戶如何最高效的生成出他們想要的圖片。
基于良好的產品和社區體驗,MidJourney 的付費用戶量也是目前最大的。
目前收費模式采用了訂閱制,個人用戶有兩個檔位,每月最多 200 張圖片(超額另收費)的 10 美元/月,以及”不限量“圖片的 30 美元/月;對企業客戶,單人一年收費僅有 600 美元,且生成的作品可以商用(當前法規尚不完善,仍可能存在一定版權問題)。
(3)Stable Diffusion
如果說 MidJourney 是一個勤勤懇懇的績優生,那么 Stability.ai 則是天賦異稟技術力強、誕生之初就備受 VC 追捧的富二代,公司估值已達到十億美元。產品 Stable Diffusion 首要目標是一個開源共創模型,與當年的 Hugging Face 神似。
創始人 Emad 之前是對沖基金經理,用自己充裕的資金聯合 LMU 和 Runaway ML開發了開源的 Stable Diffusion,在 Twitter 上使用扎克伯格在 Oculus 發布會上的照片作為背景,號召SD會成為”人類圖像知識的基礎設施“,通過開源讓所有人都能夠使用和改進它,并讓所有人更好地合作。
Stable Diffusion 可以認為是一個開源版本的DALL·E2,甚至不少使用者認為是當前生成模型可以使用的最佳選擇。官方版本部署在官網 Dream Studio 上,開放給所有用戶注冊。
相比其他模型,有很多可以定制化的點。不過官網只有 200 張免費額度,超過需要付費使用,也可以自行使用開源 Colab 代碼版無限次使用。此外,Stable Diffusion 在壓縮模型容量,希望使該模型成為唯一能在本地而非云端部署使用的 AIGC 大模型。
05 AIGC大模型的未來展望 1、應用層:多模態內容生成更加智能,深入各行業應用場景
上述的多模態圖片生成產品當前主要局限于創作畫作的草圖和提供靈感。在未來待版權問題完備后, AIGC 內容能進入商用后,必然會更深入地與業界的實際應用進行結合:
以游戲行業為例, AI 作畫給了非美術專業工作者,如游戲策劃快速通過視覺圖像表達自己需求和想法的機會;而對美術畫師來說,它能夠在前期協助更高效、直接地嘗試靈感方案草圖,在后期節省畫面細節補全等人力。
此外,在影視動畫行業、視頻特效領域,甚至是文物修復專業,AI 圖片生成的能力都有很大想象空間。當然,這個領域 AI 的能力也有著不小的進步空間,在下面的未來展望部分進行闡發。
目前 AIGC 存在 Prompt Engineering 的現象,即輸入某一些魔法詞后生成效果更好。這是目前大模型對文本理解的一些缺陷,被用戶通過反向工程進行優化的結果。未來隨著語言模型和多模態匹配的不斷優化,不會是常態,但中短期內預期Prompt Engineering 還是得到好的生成內容的必備流程之一。
2、模態層:3D生成、視頻生成 AIGC 未來3-5年內有明顯進步
多模態(multimodal)指不同信息媒介之間的轉換。
當前 AI 作圖過程中暴露的問題會成為視頻生成模型的阿喀琉斯之踵。
例如:AI 作畫的空間感和物理規則往往是缺失的,鏡面反射、透視這類視覺規則時常有所扭曲;AI 對同一實體的刻畫缺少連續性。根本原因可能是目前深度學習還難以基于樣本實現一些客觀規則泛化,需要等待模型結構的優化進行更新。
3D生成領域也有很大價值:3D 圖紙草圖、影視行業模擬運鏡、體育賽場現場還原,都是 3D 內容生成的用武之地。這一技術突破也漸漸成為可能。
2020年,神經輻射場(NeRF)模型發布,可以很好的完成三維重建任務:一個場景下的不同視角圖像提供給模型作為輸入,然后優化 NeRF 以恢復該特定場景的幾何形狀。
基于該技術,谷歌在2022年發布了 Dream Fusion 模型,能根據一段話生成 360 度三維圖片。這一領域當前的實現效果還有優化空間,預期在未來3-5年內會取得突破性進展,推動視頻生成的進步。
3、模型層:大模型參數規模將逼近人腦神經元數量
近年的大模型并未對技術框架做顛覆性創新,文本和圖像生成領域在大模型出現前,已有較成熟方案。但大模型以量變產生質變。
從神經網絡角度看,大腦有約 100 萬億神經元, GPT-3 有 1750 億參數,還相差了 1000 倍的數量級,隨著算力進步可以發展的空間還很大。
神經網絡本質是對高維數據進行復雜的非線性組合,從而逼近所觀測數據分布的最優解,未來一定會有更強的算力、更精妙的參數堆疊結構,來刷新人們對AI生成能力的認知。
4、成本結構決定大模型市場的馬太效應
大模型最直接的成本便是能源成本(energy cost),GPT-3 發布時的訓練成本在千萬美元級別。難以在短期內衡量 ROI ,大科技公司才能訓練大模型。
但隨著近年模型壓縮、硬件應用的進步,GPT-3 量級的模型成本很可能已降至百萬美元量級,Stable Diffusion 作為一個剛發布一個月的產品,已經把原本 7GB 的預訓練模型優化壓縮至 2GB 左右。
在這樣的背景下,算力成本在未來必然會逐漸變得更合理,但 AIGC 領域的另一個成本項讓筆者對市場結構的預測還是寡頭壟斷式的。
大模型有明顯的先發優勢,來自巨大的隱形成本:智能成本。前期快速積累用戶反饋數據能幫助模型持續追新優化,甩開后發的競爭者,達到模型性能的規模效應。
AI 的進化來自于數據的積累和充分吸收。深度學習,乃至當前的所有機器學習都是基于歷史預估未來,基于已有的數據給到最接近真實的可能。
正如前文討論的,OpenAI 的目標從來不是留戀于某個局部行業的商業產品,而是通過模型規模經濟,不斷地降低人類社會全局的智能成本,逼近通用人工智能 AGI。規模經濟正體現在智能成本上。
5、虛擬世界的 AGI 會先于現實世界誕生
從更宏觀的視角上,虛擬世界 AI 技術的智能成本比現實世界中來得低得多。現實里 AI 應用最普遍的是無人駕駛、機器人等場景,都對 Corner Case 要求極高。
對于AI模型而言,一件事超過他們的經驗范疇(統計上out of distribution),模型將立馬化身人工智障,不具備推演能力。現實世界中 corner case 帶來的生命威脅、商業資損,造成數據積累過程中極大的試錯成本。
虛擬世界則不同,繪圖時遇到錯位扭曲的圖片,大家會在 Discord 中交流一笑了之;游戲 AI 產生奇怪行為,還可能被玩家開發出搞怪玩法、造成病傳播。
因此虛擬世界,尤其是泛娛樂場景下的 AIGC 積累數據成本低會成為優勢。這個領域的 AI 如果節省人力、生成內容產生的商業價值能大于算力成本,能很順暢地形成低成本的正向循環。
伴隨著另一個重要的革新——長期 Web3.0元宇宙場景下新內容經濟生態的形成,虛擬世界內容場景下的 AI 很可能更早觸及到 AGI。
金色早8點
金色財經
Odaily星球日報
歐科云鏈
Arcane Labs
深潮TechFlow
MarsBit
澎湃新聞
BTCStudy
鏈得得
來源:《Testnet Wave 2 Recap - Network Learnings》by SUI Network編譯:SUI World DAO2月28日.
1900/1/1 0:00:00前言:2022 年,FTX暴雷之后,日本、韓國、美國、新加坡等多個地區對加密行業監管政策收緊.
1900/1/1 0:00:00Evmos 是 Cosmos 多鏈生態系統中一個兼容 EVM 的區塊鏈,專為跨鏈 dApp 開發而設計,使命是為未來跨鏈應用程序提供所需的基礎工具.
1900/1/1 0:00:00原文作者:William M. Peaster本文中,作者將分享創作者可以采用的四種途徑,以便在這個不斷變化的 NFT 版稅環境中更好地定位.
1900/1/1 0:00:00但見一三尺小兒,紅口白牙,腳踩風火輪,手持紅纓槍,刷刷刷舞一套槍法,竟自朝向人高馬大的Opensea心口窩刺來。這小兒,便是Blur的創始人,匿名而神秘的Pacman(吃豆人).
1900/1/1 0:00:00去年11月,由OpenAI公司發布的大型聊天機器人軟件ChatGPT“一夜躥紅”,上線短短兩三個月,用戶規模或已超過1億.
1900/1/1 0:00:00


